
RT-1
 )
)
一、Motivation
从大型、多样化、任务无关的数据集中迁移知识,以 zero-shot 或使用少量任务相关的数据集达到高水平的性能来解决特定的下游任务。实现实时控制。
二、Methdology
开放式的任务无关训练,高容量高效率架构
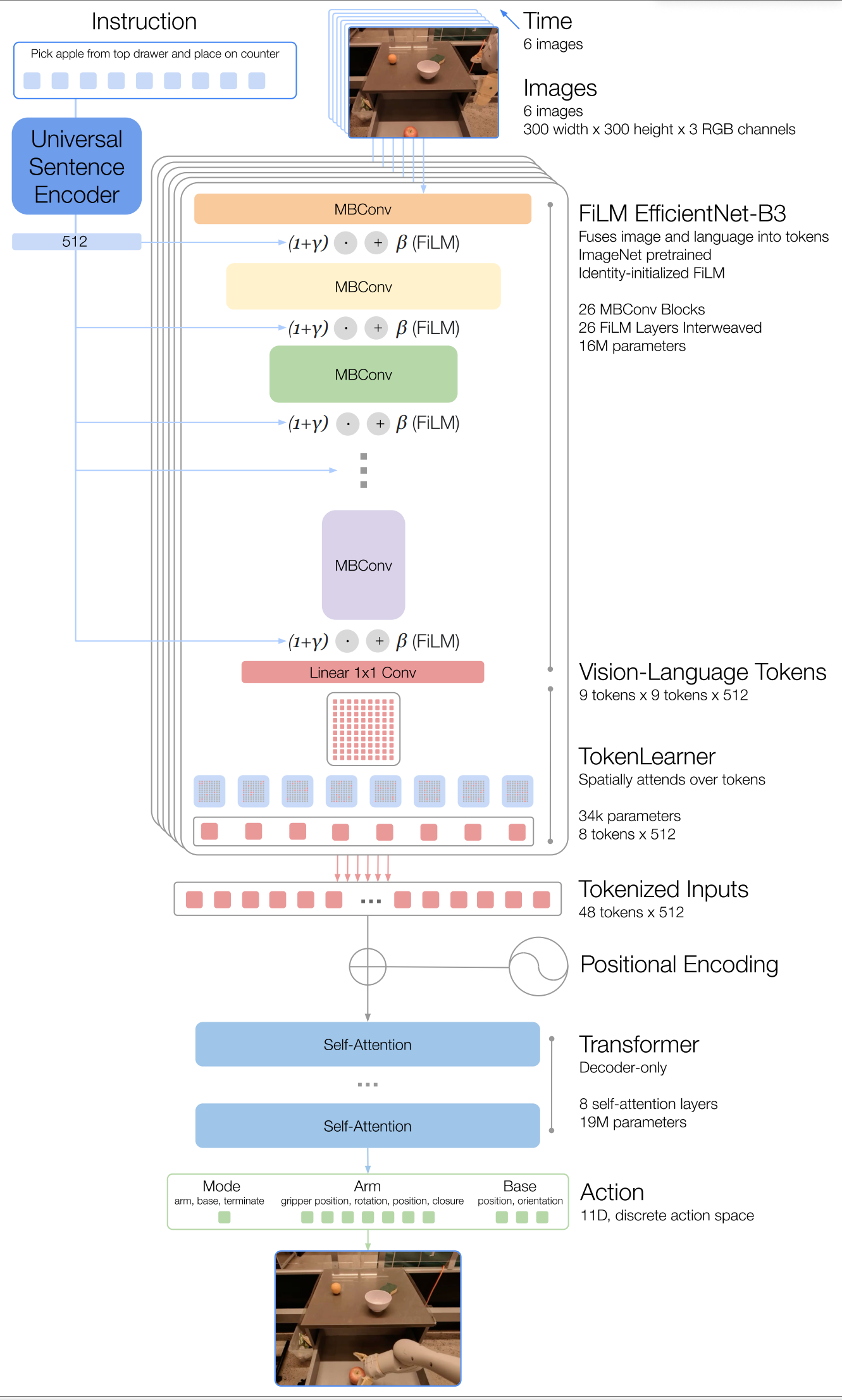
三、Architecture
image encoder
1.EfficientNet
由于RT-1要实现3HZ的动作输出频率,所以要保证推理时间不能太长。
在一定的预算内,对于卷积网络来说,增加深度能学到更丰富的特征,但是更难训练;增加宽度能学到更丰富,更细粒度的表示,但是难以学到更深层次的特征。
这个模型大概就是用网格搜索找到了模型的某个宽度(通道数,也就是卷积核个数)和深度(层数)的配置使其得到最高的准确率。
2.language-conditioned
在提取特征时,讲语言指令迁入后的向量通过FiLM层(大概是几层FFN),得到每一层特征的仿射系数对EfficientNet 的中间特征进行缩放/偏移。
这样,图像特征的提取过程会被“调节”,让网络更关注与指令相关的区域或语义。
在训练时,FiLM层使用零初始化(使其成为恒等映射),为了避免一开始就破坏预训练模型的权重。
text encoder
1.Universal Sentence Encoder
以下是AI的解释
- 语义编码:将文本从其原始的离散符号形式(单词序列)映射到一个连续的向量空间中。在这个空间中,语义相似的文本其向量距离(如余弦相似度)也更近。
- 维度统一:无论输入文本多长,USE 都会输出一个固定维度的向量(例如 512 维或 1024 维),这极大地简化了后续处理步骤。
- 多任务通用性:通过在多种任务和庞大语料库上进行预训练,USE 学习到的向量表示具有高度的通用性和迁移性,可以直接用于新的、未见过的任务(即零样本或少样本学习)。
tokenlearner
将编码的81个image token变成8个,进一步提高推理速度
action tokenize
arm 7个维度(x,y,z,roll,pitch,yaw,the opening of gripper)
base 3个维度(x,y,yaw)
一个离散维度用于在三种模式之间切换:控制机械臂、底盘或终 止回合
每个维度量化为256个bin。
loss function
将bin视为class计算多类交叉熵。
training
训练时一次生成一个时间步的所有动作维度,而不是逐维度生成,提高速度。
四、conclusions
- 数据集的多样性对泛化能力的影响大于数据集的规模
- 使用预训练的编码器会是模型继承一些泛化能力
- 动作表示方式对模型的性能在几乎所有任务上都有影响。论文中对每个维度离散化使其能表示复杂的多模态动作,而传统的从高斯分布中取样的方式只是但模态的。(这里只能大概理解一下,并不懂为什么传统方法要从高斯分布中取样)
- 前期的语言融合相比于后期来说使处理图像时聚焦于不同区域,对distractor的抗性更强。
五、Some Comments
- 这里的模态对齐主要在FiLM这一步,它可以在训练时将语言中的信息融进特征提取。我觉得它的主要效果在于能突出我们的目标物体,使后续在干扰物鲁棒性测试中表现优异。还有一个点是用了预训练过的text encoder,我觉得这里起到的仅仅是一个良好的初始化作用(也许能少训练几步?),但是并不能对未见物体和技能的泛化有什么作用,因为未见物体和技能根本没有和图像对齐。而事实上作者在总结里也承认了这一点。事实上感觉并没有太发挥预训练模型的作用,也许可以改进,还有就是仅仅将语言最后编码为一组系数感觉信息融合地还不够,但是也不太清楚还能怎么融合。
- 我们注意到最后在输出action时,输入的仅仅是视觉token,仅仅学习视觉(当然这里是经过语言指导的视觉)到动作的映射,感觉上也许应当要比视觉-语言到动作的映射更简单,毕竟只需要对齐两个模态。
- 那么为什么仅用视觉就可以生成动作?也许在不断的训练中,我们教会了模型看到半开的抽屉就把它拉开(为了和关上区分,也许我们还要看历史信息,比如说一开始是开的还是关的),看到倒下的瓶子就把它扶起来等。策略学习“如何从当前状态到达目标状态”
- 从消融实验中可以发现,对泛化影响最大的就是pre-training,其次是continuous actions,其他的都不明显。我不太理解为什么是这样 可能的原因是预训练使得对指令和物体的编码更好,使得其更容易迁移。
- RT-1 之所以能实现异构数据吸收,源于其架构的精心设计:(AI的解释)
- 统一的表示空间:通过语言指令(如“pick anything”)和图像观测作为桥梁,将不同来源的数据映射到同一个高维表示空间中。模型学习的是“指令-观测-动作”的通用映射关系,而非过拟合到特定的机器人动力学或环境外观。
- 强大的序列建模能力:Transformer 架构本身具有极强的数据吸收和模式匹配能力,能够处理和理解分布差异较大的数据。
- 动作空间对齐:在融合 Kuka 数据时,论文将 Kuka 的原始动作空间对齐(project) 到 RT-1 的标准化动作空间(如将4-DOF转换为7-DOF,并离散化),这是实现有效迁移的关键预处理步骤。
- 这说明人工的设计越少就越接近本质
RT-2
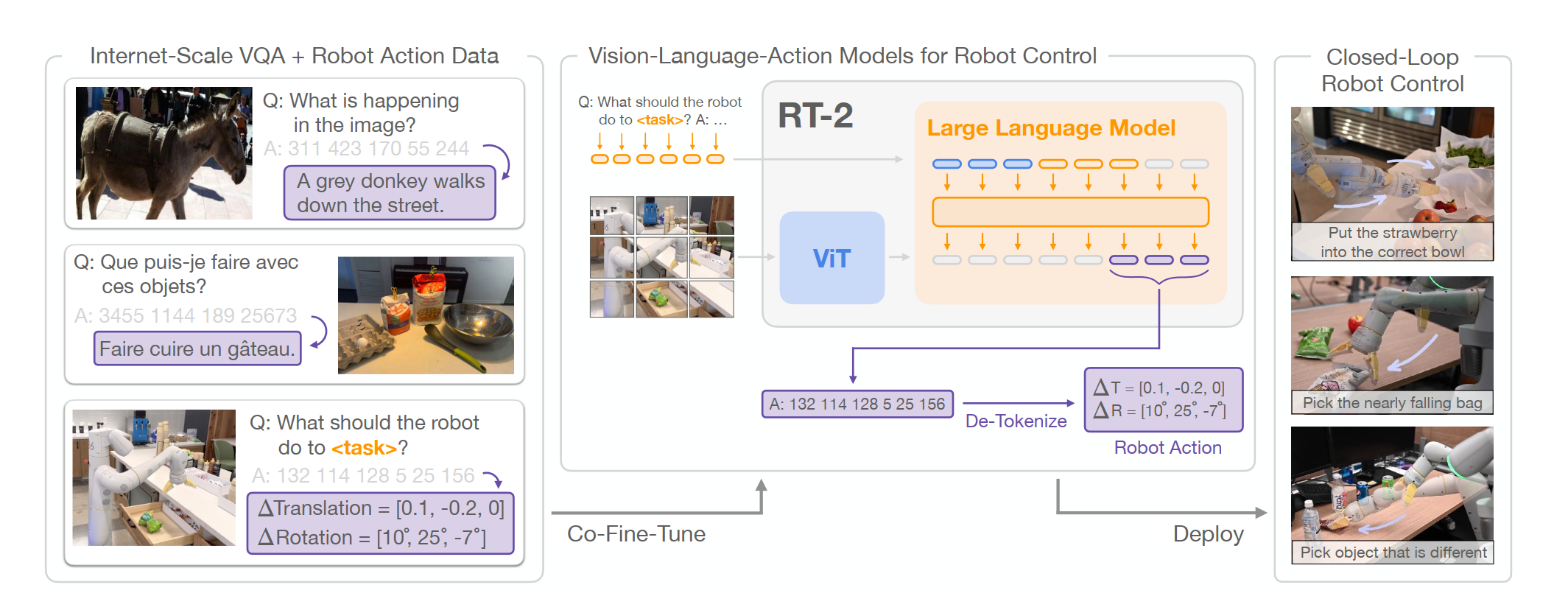
一、Motivation
这个工作是想将大型的预训练模型融合进去(之前RT-1的预训练模型还比较小),以产生像gpt之类的惊人能力。而之前考虑融合大模型的工作都只是将其作为action paser,在一个high level上将任务分解为基本动作,再交给底层执行器去执行,比如,指令:“把杯子放到桌子上” → 解析成 [抓取杯子] → [移动到桌子] → [放下杯子]。并没有真正地将大型预训练模型融入动作生成之中。并且作者希望能使用网络上的海量数据来进行微调。 但是说实话谁能像Google一样去微调这么大的模型呢
二、Methodology
研究者们把原本用于 开放词汇视觉问答(VQA) 和 视觉对话 的大规模视觉‑语言模型(VLM),直接训练成能够输出机器人低层动作的模型,同时还继续保留它在互联网上各种视觉‑语言任务上的能力。
具体来说就是把语言-视觉-动作统一为token,构成一个“multimodal sentence”便于像输出语言一样自回归地由语言和视觉token产生动作token.(这好像和Gato做的是同一件事,但是更专注于动作的输出)
三、Architecture
采用了PaLI-X和PaLM-E两种VLM模型
PaLI-X是vit+UL2(UL2是encoder-decoder架构,采用混合预训练任务的语言模型)
PaLM-E是vit+decoder-only LLM(专注于将高层次机器人任务分解为机器人可执行的低层次步骤)
为了使视觉-语言模型能够控制机器人,它们必须被训练以输出动作。作者采用直接的方法来解决这 个问题,将动作表示为模型输出中的词元,这些词元以与语言词元相同的方式处理。并且动作编 码基于 RT-1 模型提出的离散化方法。
两种将动作整合为token的方式:
- 对于 PaLI-X,每个不超过1000 的整数都有一个唯一的词元,因此我们只需将动作区间与对应整数的词元关联起来。
- 对于不提供这种方便的数字表示的PaLM-E模型,我们仅将256个使用频率最低的词元覆盖以表示动作词表。
四、Training Strategy
联合微调:既在机器人数据上微调,也在VQA上微调,通过加权采样保证平衡每个训练批量中机器人数据和网络数据的比例。
五、Limitations
- 无法泛化到新动作
- 计算复杂度高,速度慢
六、Some Comments
- RT-2由于参数很多,推理速度仅有1-3HZ,非常慢。
- RT-2能通过CoT进行先高层规划再底层执行,实现复杂动作
- RT-2表现出了非常强的涌现能力,比如Taylor Swift时刻。出现这种情况我们也许可以简单将其理解为:VLM的大量预训练赋予了模型在新物体上的泛化(因为这是VLM本身就具有的能力)。最简单的情景:将物体A移到物体B上。模型在训练中获得move技能只依赖于AB的位置等,并不依赖于它们是什么,而获取位置信息的能力由VLM赋予,这样就很容易泛化到新物体上。但是很明显这无法泛化到新的动作上(因为这必须要从训练中获得)。
RT-Trajectory
一、Motivation
这个工作很明显是接续RT-1和RT-2,探索对于新动作的泛化。
目前现有模型采用语言条件(如FiLM)在动作的泛化上并不理想。例如,在拾取和放置任务上训练的语言条件策略无法泛化到折叠任务,即使折叠的手臂轨迹与拾取和放置相似。
注: 作者在这里给了一个我认为比较好的insight:“策略条件化不仅影响任务指定的实用性,还可能在推理时对泛化产生重大影响。如果任务的表示与训练任务的表示相似,潜在模型更有可能在这些数据点之间进行插值。这通常体现在不同条件化机制展现的泛化类型上——例如,如果策略基于自然语言指令进行条件化,它可能泛化到文本指令的新表述,而同一策略在训练于拾取放置任务时,即便折叠动作的臂部轨迹与拾取放置相似,也难以泛化到折叠任务,因为在语言空间中,这一新任务超出了先前所见数据的范围。” 这有助于我们从直觉上理解为什么这些策略会得到这样的泛化效果。
二、Related Works
这篇文章主要研究泛化方面的问题,并且在related work中将这方面比较好地介绍了一下:
-
Robotic Learning中的泛化性问题:
- 2D 控制问题,探讨机器人在二维环境下学习控制策略时的泛化难题,比如从有限的演示中学到的动作能否推广到新的场景。
- 演示质量,研究演示数据的好坏对模仿学习的影响。高质量、干净的演示能帮助模型学得更好,而低质量或含噪声的演示会严重影响泛化。
- 视觉分布偏移,分析当训练和测试时的视觉输入分布不一致(例如光照、背景、物体外观变化)时,模仿学习策略的泛化能力会下降。
- 动作一致性,研究机器人在执行任务时,动作是否保持一致性和稳定性。如果策略在相似场景下输出的动作差异很大,就会导致泛化失败。
-
之前的工作提出的验证泛化能力的标准: 泛化到新的语义属性、变化的语言模板(动作不变,仅变化语言表述)、未见过的物体类别、新背景和干扰物、分布变化的组合、开放集语言指令以及网络规模的语义概念。
-
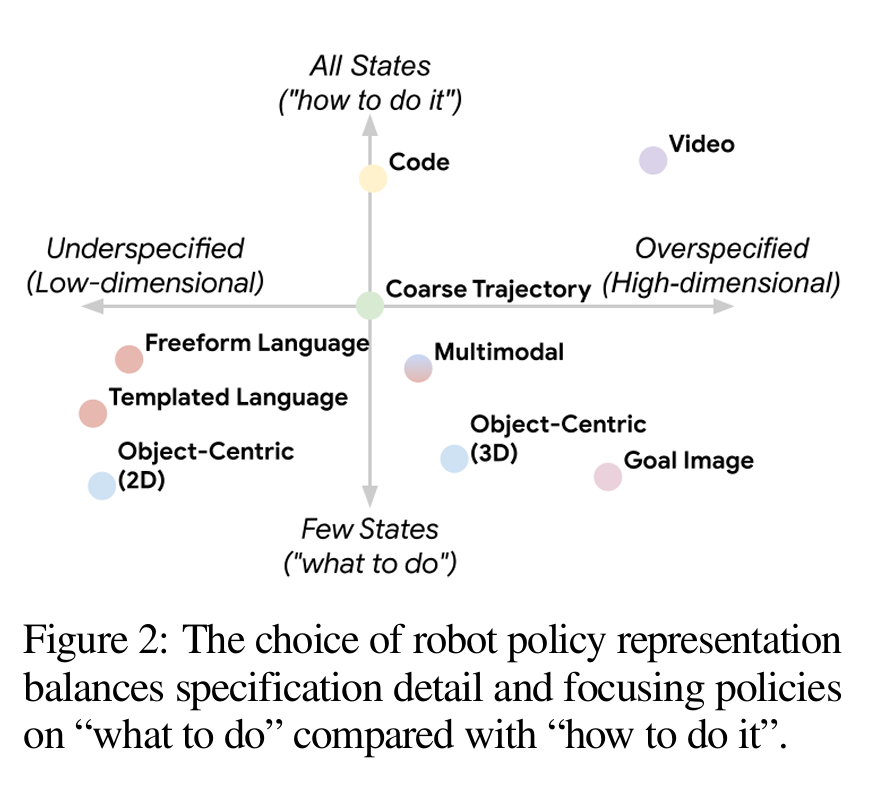
之前的工作在策略条件化方面的探索:
- one hot 条件化,无法泛化
- 语言条件,不够细,难以描述新动作。语言条件化策略可以被视为在最终状态上不足指定(例如,完成拾取罐子的策略可能存在多种可能的最终状态)
- 目标图像目标图像条件化策略可以被视为在最终状态上过度指定(即“做什么”),因为它们定义了整个配置,其中一些可能并不相关。例如,目标图像的背景像素可能与任务无关,反而包含多余信息。
- 视频,维度太高,难学
- 这些方法主要考虑两个方面:
- 目标的过度指定与不足指定
- 对轨迹中所有状态进行条件化还是仅对最终状态进行条件化。
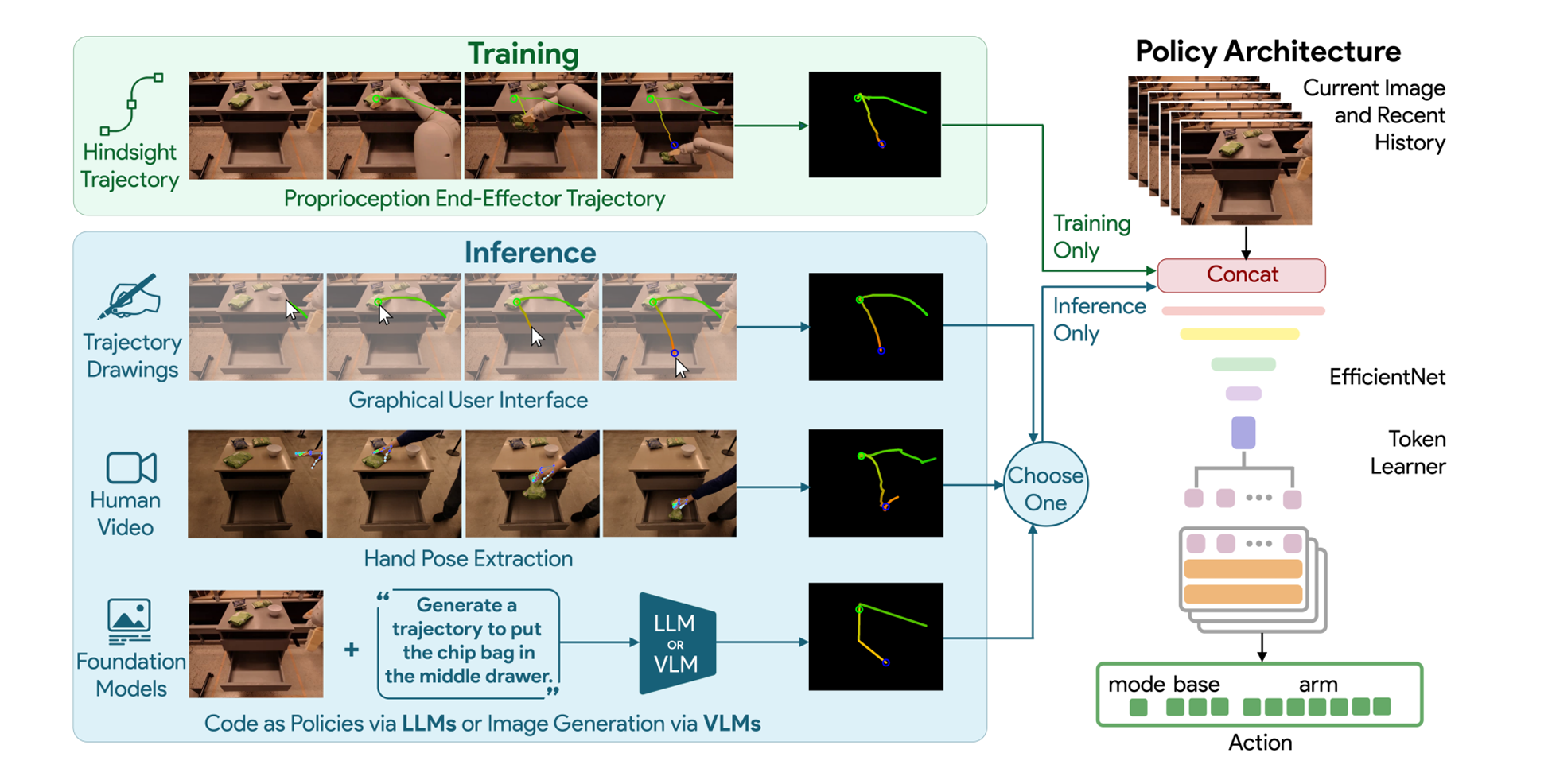
三、Methodology
所以作者提出了使用粗略轨迹的条件策略化,这是一种中等粒度的任务指定,既不会欠拟合也不会限制其泛化能力。
其轨迹的绘制需要一些trick,比如说通过图片在不同通道上的变化来表示时间和高度,圈表示夹爪和物体的交互。
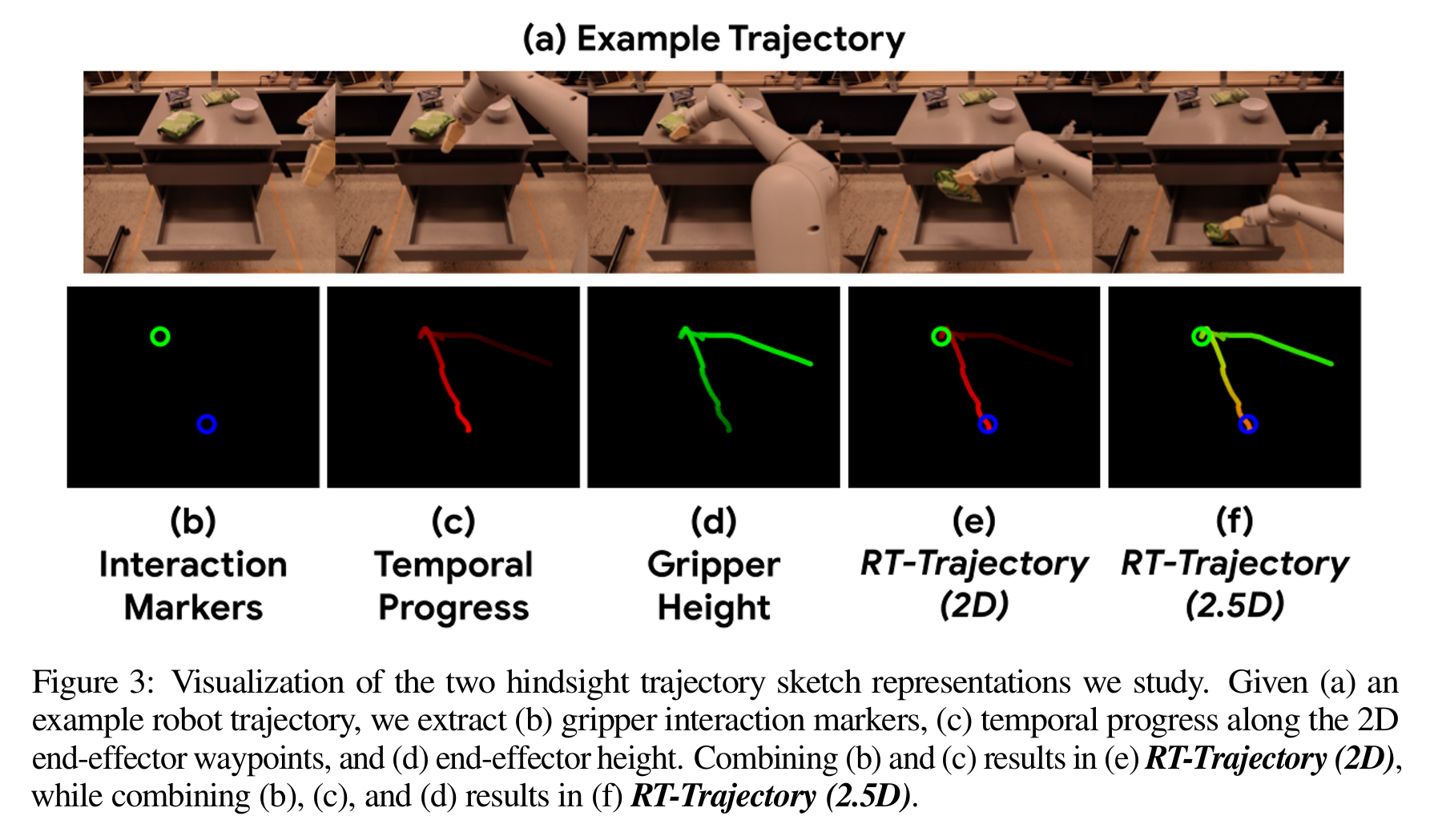
此外,作者研究了四种不同的方法来生成轨迹草图:手绘草图、人类视频、使用代码作为策略提示LLMs以及图像生成模型
四、Architecture
和RT-1差不多,进行如下改动:
- 把轨迹草图和 RGB 图像在特征维度上拼接
- 这里没有语言输入,所以直接移除了 FiLM 模块。
五、Conclusions
- 首先,当前我们假设机器人保持平稳,仅使用末端执行器来完成有效的操控动 作。将这一理念可以扩展至允许机器人通过全身控制进行操作的移动操控场景
- 用户可能希望指定某些空间区域,在这些区域内指导需被更严格地执行,例如在移动过程中避开易碎物品。因此,一个有趣的未来方向是使系统能够利用轨迹草图来处理不同类型的约束
六、Some Comments
- 感觉有一个明显的问题是,生成sketch太过于麻烦了,可以做一套自动化的pipeline来自动生成高质量sketch。实际上这就是一个visual prompt。而且最终人们和机器人交互的方式肯定是语言,不可能是给它画sketch。这个条件还是太强了。
AutoRT
这是一个收集数据的多agent系统,但是在机器人数据集方面我还一无所知,暂时看不太懂。先鸽一下。