
Preface
这一系列工作都是由于之前的模型闭源且过于巨大,对于个人开发者很不友好,故开始利用开源的vlm做可以高效微调的vla,为社区做出贡献。
RoboFlamingo
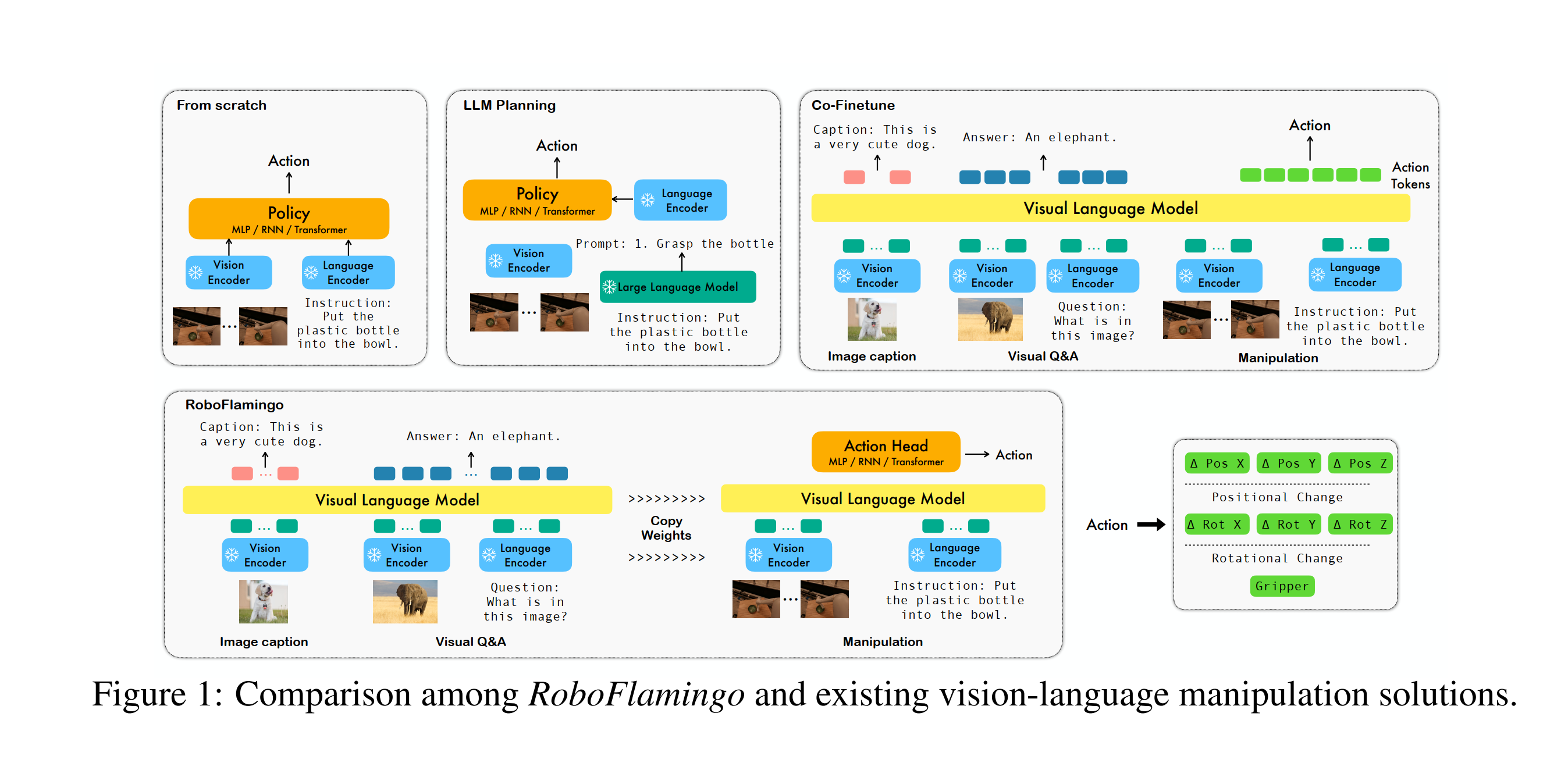
一、Methodology
为了降低RT-2那种模型的微调难度,作者没有采用RT-2那种将action也作为token对齐到语言和视觉模态空间的办法(因为这需要大量数据的微调),而是显式地用了一个policy head接受上游vlm融合以后的历史特征以输出动作。
事实上这和RT-1很像,并且这个方法在cv其他领域如分类分割中广泛地使用,就是用一个基础大模型抽特征,然后加一个head适配下游任务。
二、Architecture
Flamingo
既然模型用的vlm是flamingo,那我们就来回顾一下。
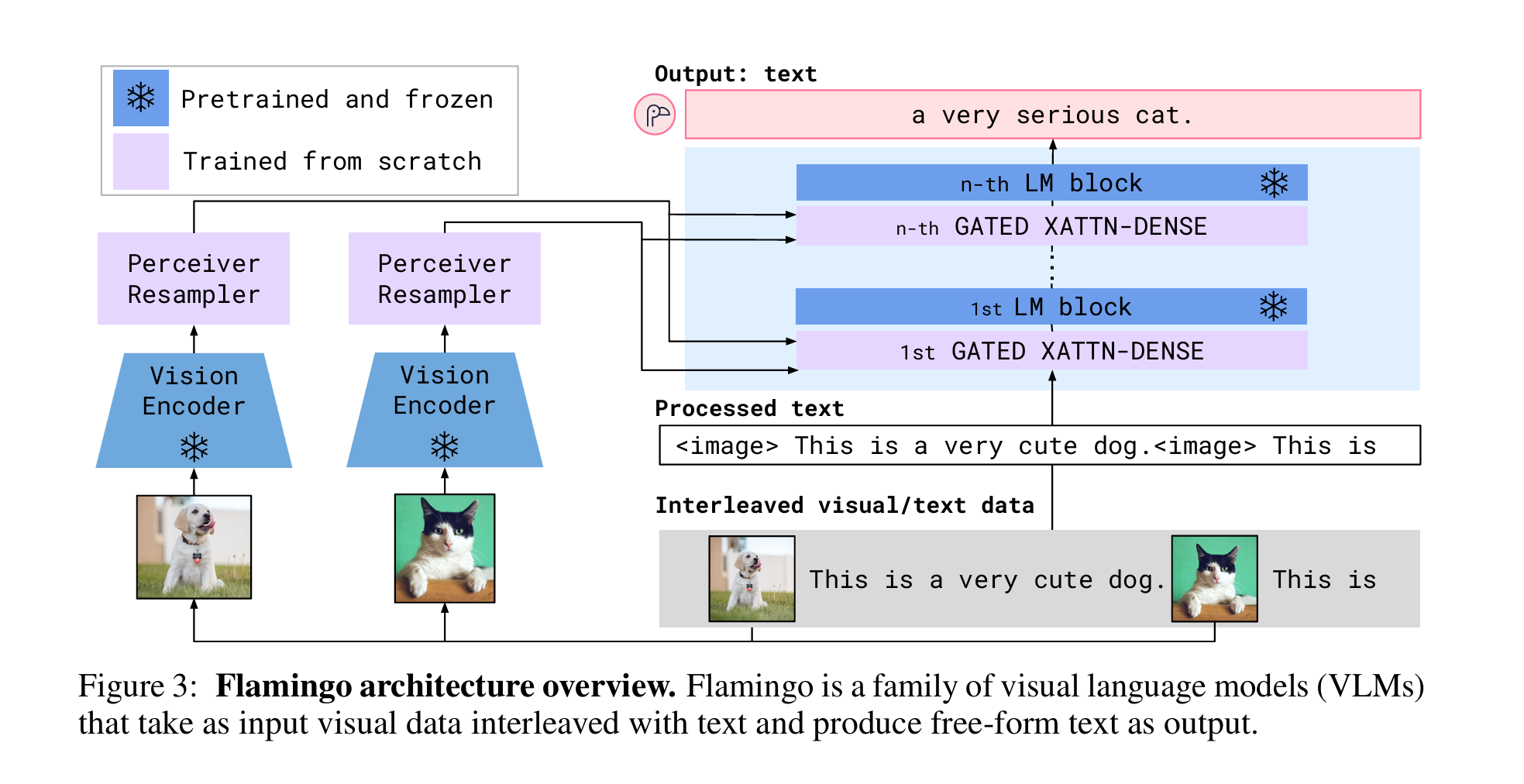
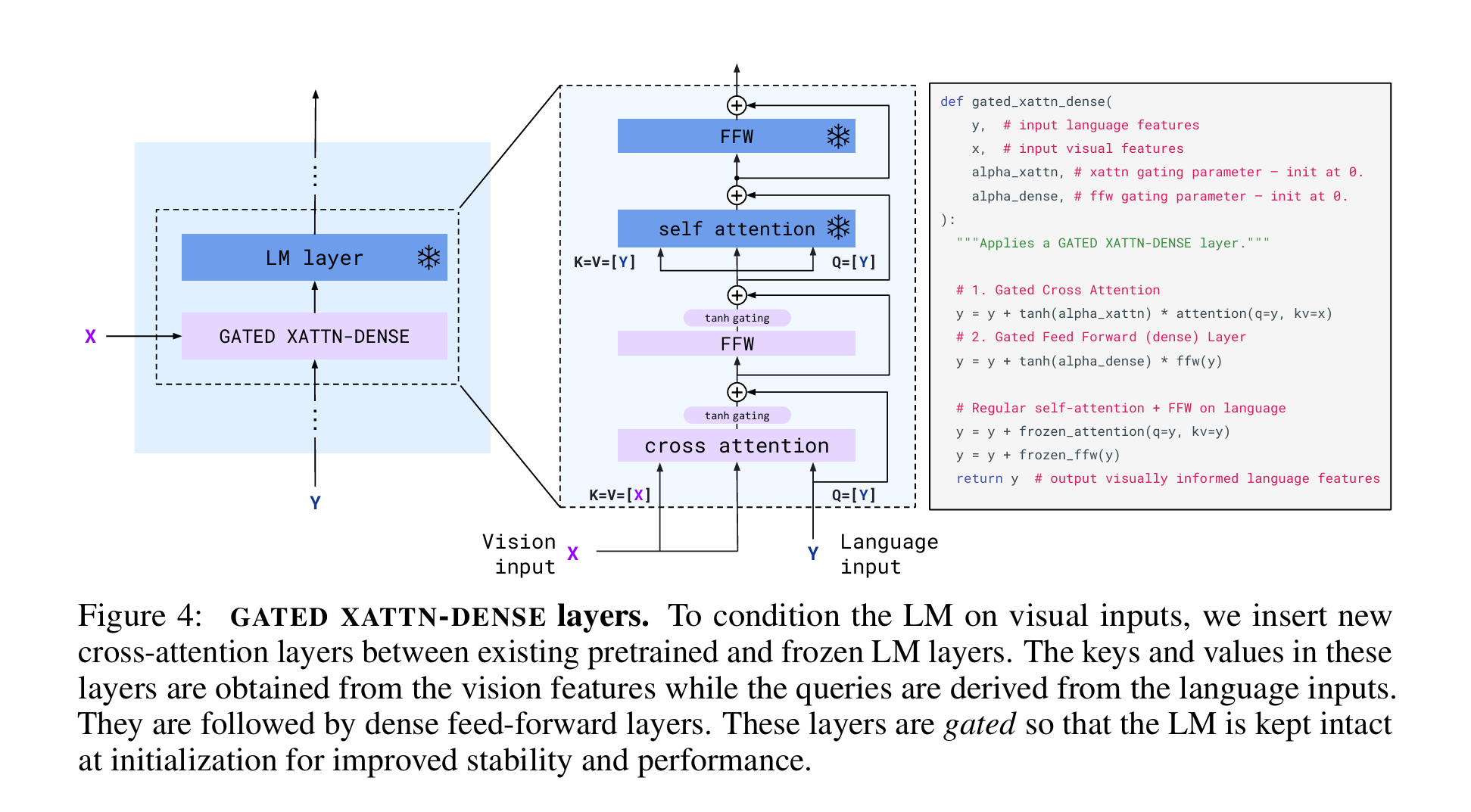
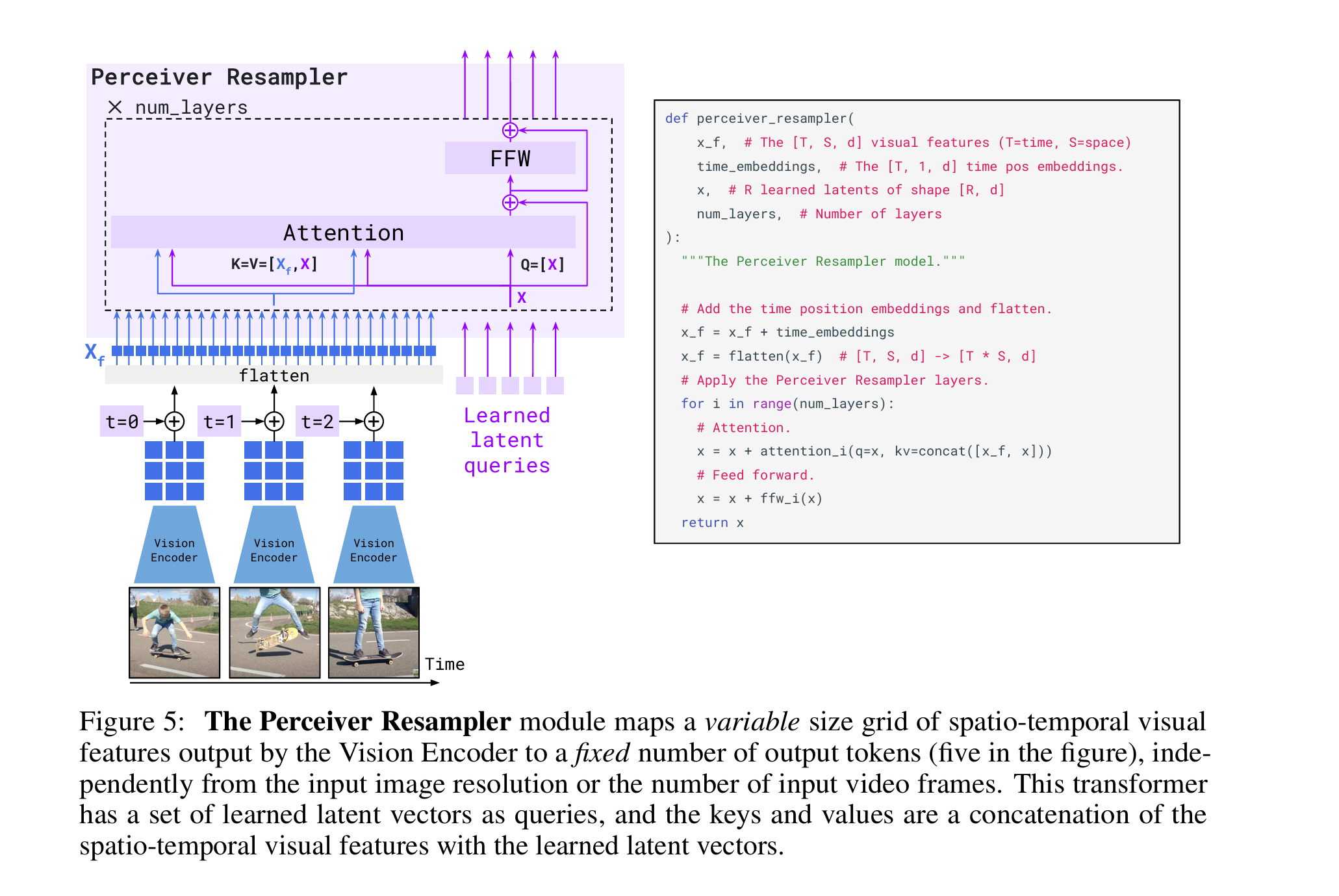 (感觉这三张图已经把架构展示得很清楚了)
(感觉这三张图已经把架构展示得很清楚了)
Policy Head
在此基础上,作者又设计了一个policy head,利用最后的视觉语言融合表征来输出动作。它解决了如下三个问题:
- 它将具有静态图像输入的视觉-语言模型适应为视频观测
- 它生成机器人控制信号而非仅文本输出
- 它需要有限的下游机器人操作数据,在拥有数十亿可训练参数的情况下实现高性能和泛化能力
policy head作者尝试了三种不同的架构:
- 纯MLP
- decoder-only transformer
- LSTM
最终的结果是LSTM最好
事实上这类似于插了一个adapter
三、Loss

四、Some Comments
- 实验部分的几个baseline都是没有用预训练的vlm,这表明RoboFlamingo确实继承了预训练vlm的一些好处。
- 感觉这个工作就是把动作生成和vlm解耦了,减少了需要训练的参数量,其他似乎没啥特别令人眼前一亮的地方
Openvla
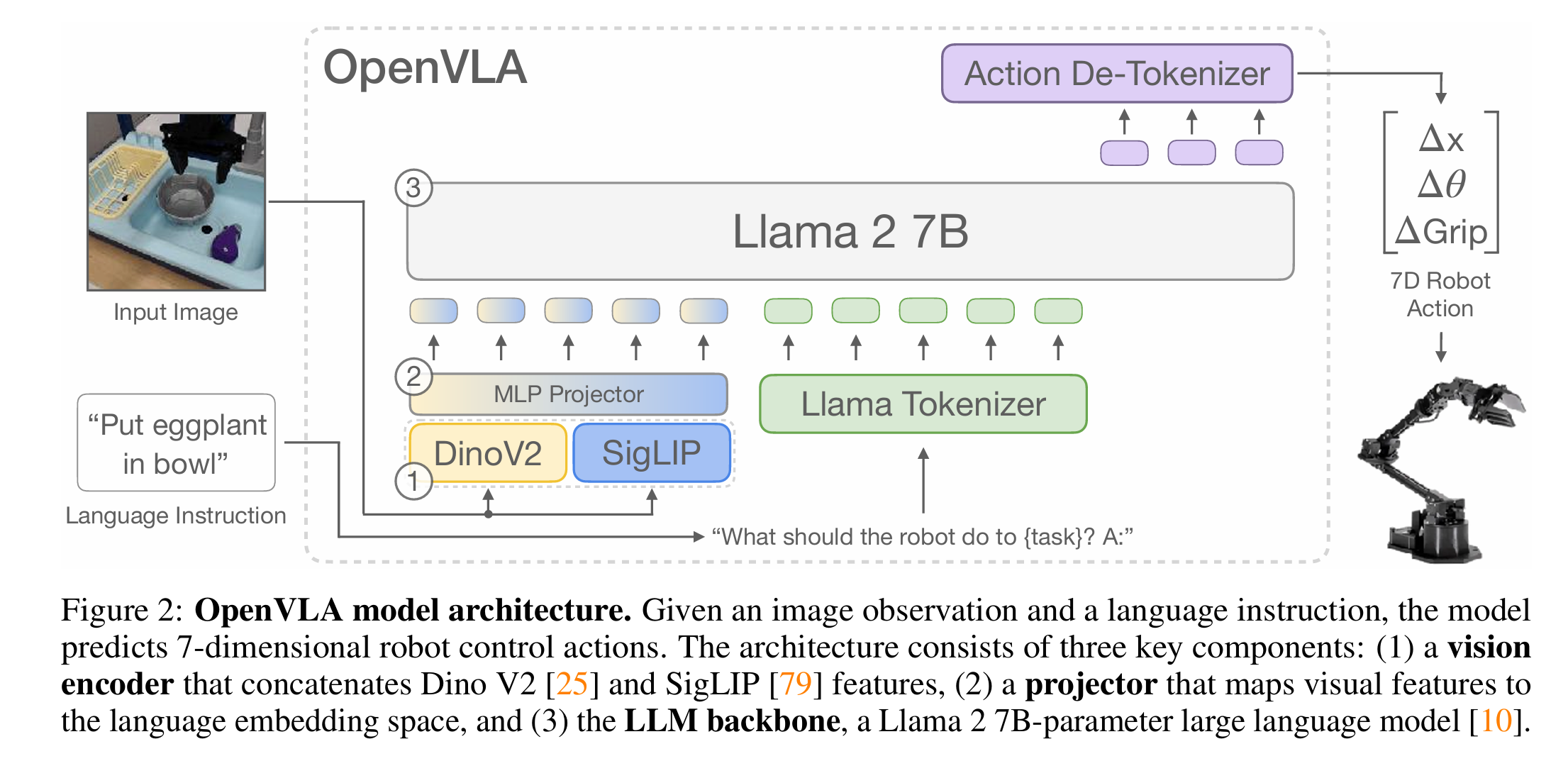
一、Methodology
Open-source
利用Llama 2作为语言编码器DINOv2和SigLIP作视觉编码器
Compute Effeciency
- low-rank adaptation method
- quantization
二、Architecture
大体结构依然遵循RT-2,不同点在于:
- image-encoder和tokenizer换掉了
- action token在设计的时候把前后1%的异常值去掉,再平均分为256个bin
- 把llama最不常用的256个token换成了action token
三、Dataset
用的是Open X-Embodiment,由于这个数据集是由社区合作产生的,包含了不同机器人、任务、场景,作者做出以下两点改进:
- 保证输入输出空间一致性:
- 包含至少一个第三人称摄像头视角的数据(便于视觉理解和泛化)。
- 使用单臂末端执行器控制的数据(统一动作空间,避免双臂或特殊控制方式带来的复杂性)。
- 保证任务、机器人形态和场景的多样性
- 降低权重或剔除那些任务和场景单一的数据集。
- 提高权重那些任务种类多、场景变化大的数据。
四、Efficiently fine-tuning
LoRA
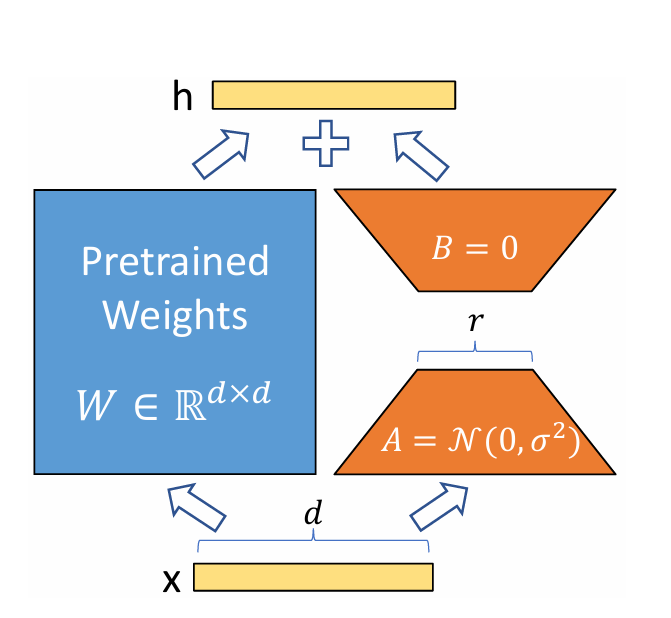
如图所示,lora的思想就是把原参数矩阵冻结,然后把微调时的更新矩阵 分解为A,B,其中A是往低维r投影的一个矩阵,B将其从r投影回来。这种操作的依据在于预训练大模型有一个极低的intrinstic dimension,也就是说在整个参数空间中微调模型和在其一个很小的子空间中微调具有相同的效果,而且越大的模型,intrinstic dimension越小。而lora就是通过向低维投影将限制在一个小的子空间中进行优化,不仅减少了参数量,还不损害性能。
通过实验,作者最后发现用lora微调以后性能和Diffusion Policy (from scratch),Diffusion Policy (matched),Octo (fine-tuned),OpenVLA (fine-tuned),OpenVLA (scratch)相比,OpenVLA (fine-tuned)在整体上取得了最好的成功率。
五、Conclusions and Limits(from paper)
- 首先是这个模型只能接收单张图像输入,未来应当拓展到多图像和多种本体感觉的输入
- 推理频率太低而无法做太灵巧的动作
- 成功率不稳定
- 以及许多有待探究的共性问题:用什么大小的vlm?机器人数据集和网络数据联合微调能显著提升性能吗?vla到底应该接受什么样的视觉特征?