生成混淆矩阵
def _generate_matrix(self, gt_image, pre_image):
# gt_image = batch_size*256*256 pre_image = batch_size*256*256
mask = (gt_image >= 0) & (gt_image < self.num_class)
# valid in mask show True, ignored in mask show False
label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]
# 这构造了一个双射,使每一个(gt_label,pre_label)唯一映射到一个整数
count = np.bincount(label, minlength=self.num_class ** 2)
# return a array [a,b....], each letters holds the count of a class and map to class0, class1...
confusion_matrix = count.reshape(self.num_class, self.num_class)
#confusion_matrix like this: and if the element is on the diagonal, it means predict the right class.
#row means the real label, column means pred label
return confusion_matrix
transform.totensor
会自动把(H,W,C)调整(C,H,W)
按行存储的二维数组与展平后的一位数组的坐标对应(索引从0开始):
(r,c)---index
r=index//height
c=index%height
model.eval()
等价于 model.train(True)
这不会禁用梯度,这个函数只是影响某些模块的行为,如:dropout,batchnorm等
影响梯度的操作
torch.no_grad()
torch.inference()
require_grad=T/F
to_device
一般在数据集里to_device,而在每个batch中,为了节约显存
张量复制
torch.tensor(sourceTensor)会创建一个新的计算图节点,可能破坏原始张量的梯度跟踪
推荐使用 clone().detach()可以更明确地控制梯度传播行为
.clone().detach()
clone()
作用:
创建一个新的张量,其数据与原始张量完全相同,但是新的张量拥有自己的存储空间(即不共享内存)。这意味着修改克隆后的张量不会影响原始张量。
与计算图的关系:
clone()操作会保留原始张量的计算图。也就是说,如果你在计算图中有一个张量,对它进行clone(),那么新张量仍然会保留梯度传播的路径,即从克隆张量反向传播到原始张量。 例如:如果a是计算图中的张量,b = a.clone(),那么对b进行运算得到的标量(例如损失)进行反向传播时,梯度也会传播到a。
detach()
作用:
返回一个新的张量,这个张量是从当前计算图中分离出来的。新张量与原始张量共享数据(即共享存储空间),但不会记录任何计算图的相关信息(即不会参与梯度计算)。 注意:在PyTorch中,共享存储意味着修改一个张量可能会影响另一个(因为底层数据是同一个),但是detach()返回的张量不参与梯度计算。
与计算图的关系:
分离出来的张量不需要梯度,即使它是由需要梯度的张量得到的。因此,它通常用于不需要计算梯度的中间结果或者固定某些张量的值(例如在迁移学习中固定预训练模型的参数)。
.clone().detach():
构建了一个不共享内存也不参与梯度计算的张量。
.detach().clone()
将原张量与计算图断开,并clone一个独立的新张量。
pandas的一些大坑
df.drop 并不会重排行索引,会造成行索引间断,后续要跟上df.reset_index(drop=True, inplace=True)
df.loc 左闭右闭(index索引)
df.iloc 左闭右开(整数索引)
Dataloader

permute,transpose,reshape,view
permute和transpose事实上就是交换stride,因为i*stride[0]+j*stride[1]+k*stride[2]就等价于j*stride[1]+i*stride[0]+k*stride[2]等等。
permute可以任意交换,transpose交换两个。
但是内存并不改变,故后续的操作如果依赖于连续内存的话需要contiguous
reshape和view修改size,再根据新size算出新stride。
view必须作用于内存连续的张量,reshape更只能,可以先contiguous再view。
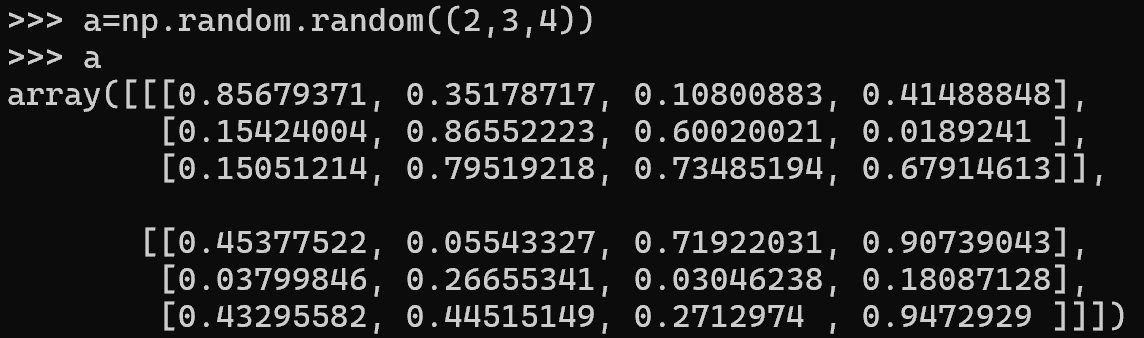
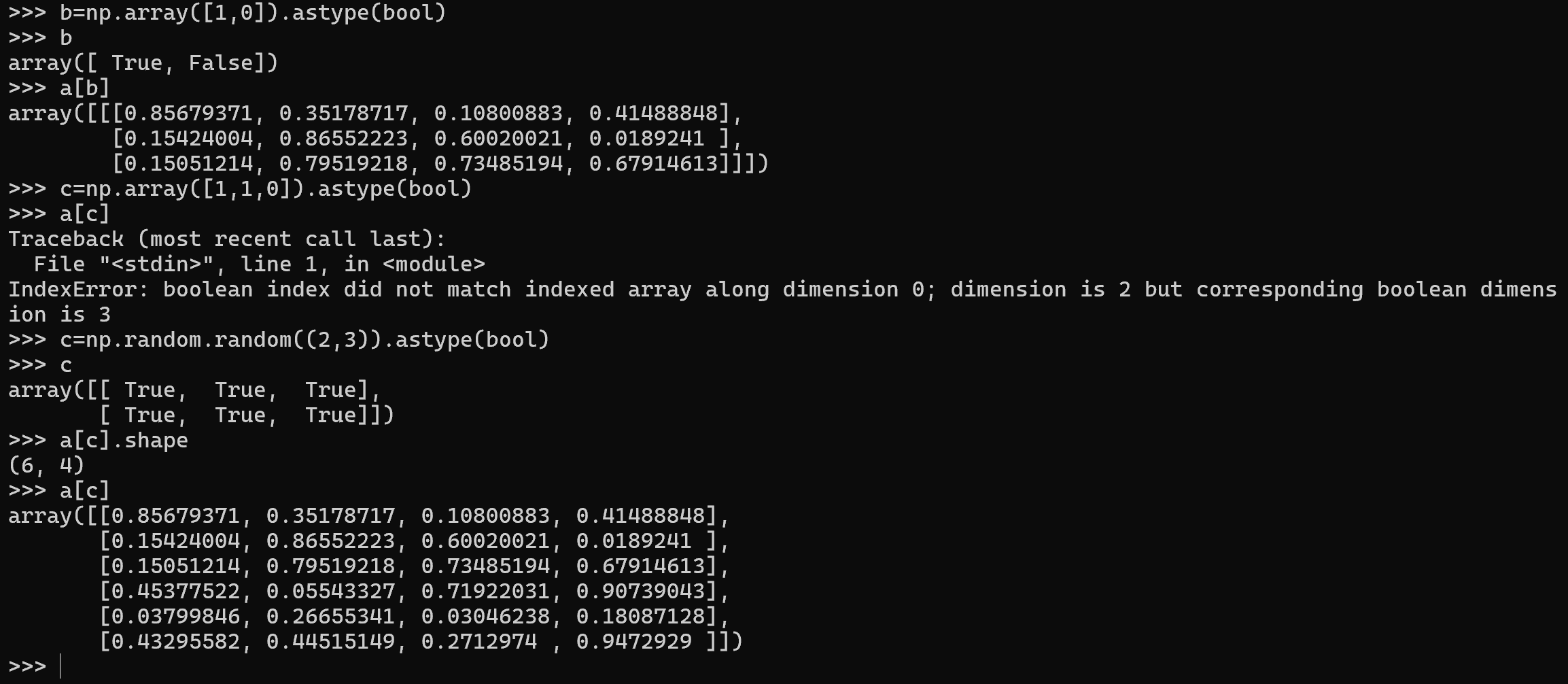
关于布尔索引的广播
np.array vs np.asarray
这两者最大的区别是当传入的参数已经是np.ndarray时,后者不再复制,而前者还要复制。所以用后者更好
约束优化
如果一个要优化的参数必须是正数的话,为了避免其变成负数,我们可以取对数后进行优化,要用的时候再取exp