视频生成主要范式为基于扩散的和基于自回归的,还有一些两者的折中,主要是解决diffusion不能流式生成的问题。
Diffusion-Based
基于扩散的方法主要是因为high fidelity和coherence,由于质量高,目前最主流的商业模型一般都是这个架构。
MovieGen&Hunyuan Video
两者结构差不多,故放在一起
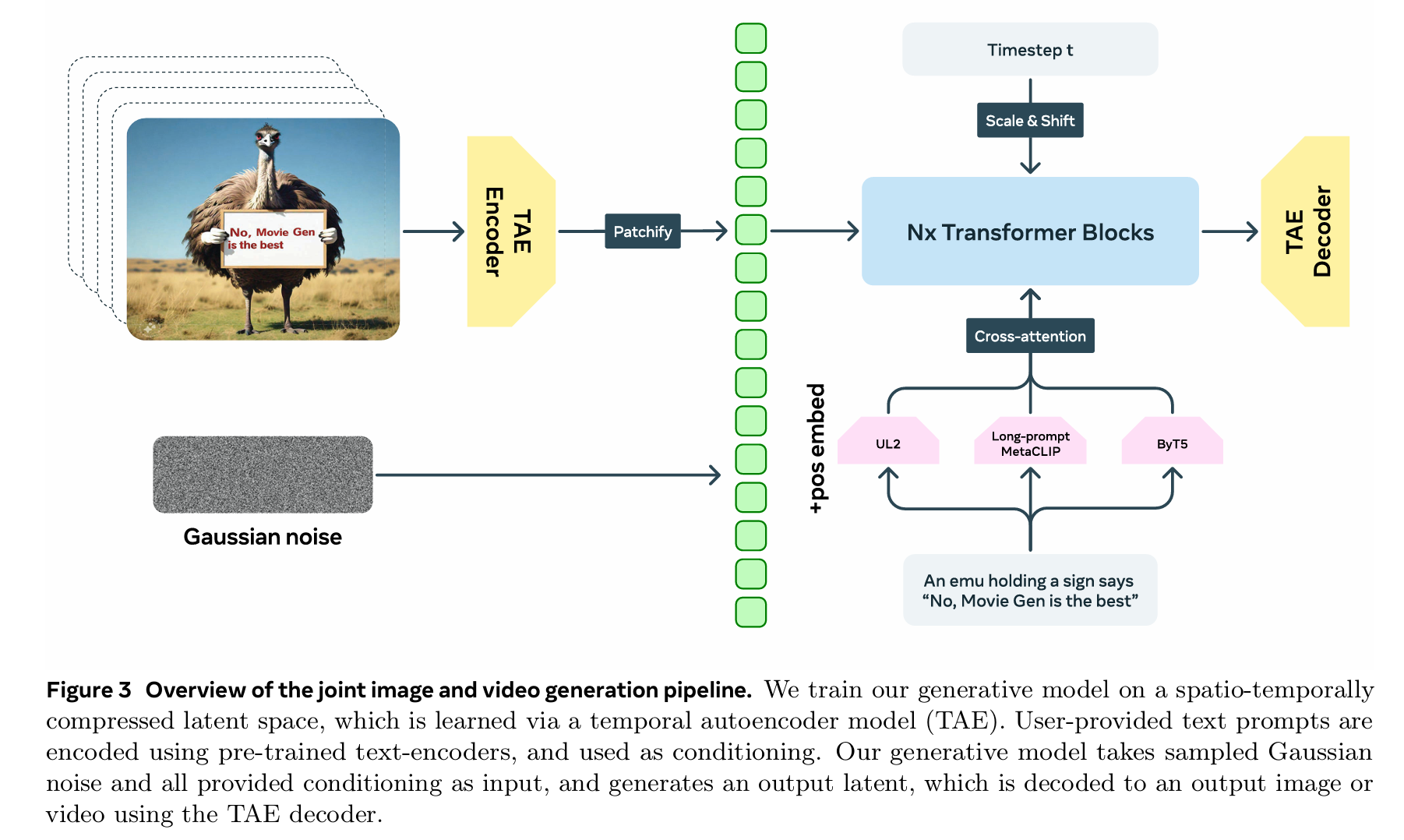
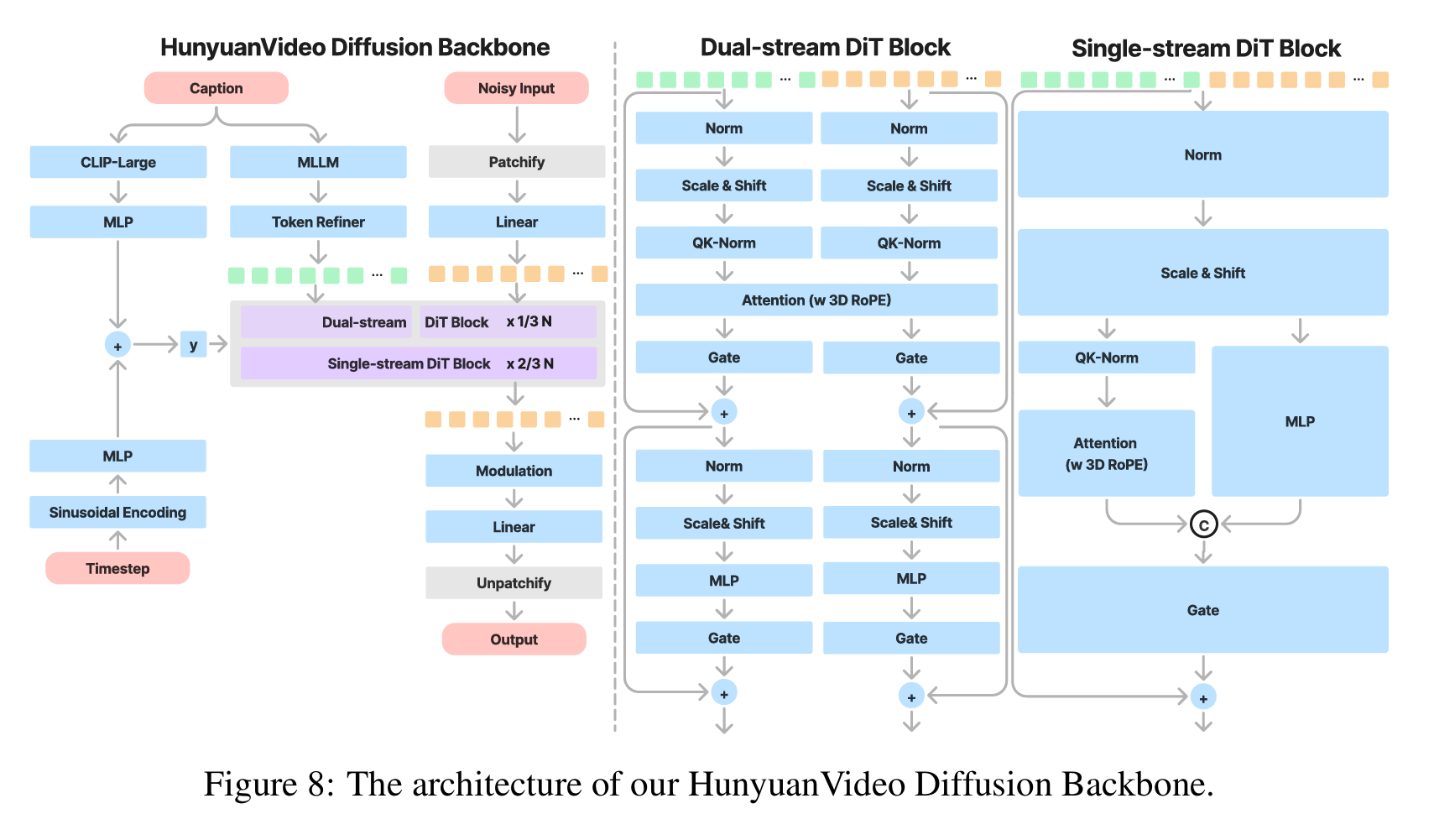
video
Training
Step 1: 视频压缩(3D-VAE 编码)
- 输入:真实视频 ,尺寸为 (T+1 帧)
- 编码器:3D 变分自编码器(同时压缩时空维度)
- 输出:潜码 ,形状为 ,其中:
- :潜码通道数
- :空间压缩率(如 8×)
- :时间压缩率(隐含在 T+1→T+1 中,通常也是 4× 或 8×)
- 本质:将像素空间视频压缩到低维潜空间,大幅减少计算量
Step 2: 条件信息准备
- 文本条件:提示词 被编码为文本潜码(通常用 T5 或 CLIP 文本编码器)
- 图像条件(可选):若做图生视频,参考图像经 3D-VAE 编码后,在通道维度上与 拼接(channel-wise concatenation)
Step 3: 前向加噪声(扩散过程)
- 对潜码 按流匹配(Flow Matching)或 RFM(Rectified Flow)方式加噪,得到任意时刻 t 的噪声潜码
- 关键:这里不是传统的 DDPM 加噪,而是在潜空间中进行插值:
- ,其中 ε~N(0, I)
- 速度真值:(这是训练目标)
Step 4: 双流到单流的 DiT 去噪
这是核心创新点,参考了 SD3 的多模态融合策略:
第一阶段:双流处理(Dual-stream)
- 视频潜码 → 拆成时空 Patch → 视频流 Transformer Block
- 文本潜码 → 文本流 Transformer Block
- 两个流独立处理,各自提取特征(避免文本被视觉信息淹没)
第二阶段:单流融合(Single-stream)
- 将双流输出在序列维度拼接(concatenate)
- 送入单流 Transformer Block ,让文本和视觉信息充分交互
- 目的:既保留模态特异性,又实现深度耦合
Step 5: 速度预测与损失
- 网络输出:预测的速度
- 监督信号:真实速度
- 损失函数:最小化均方误差(MSE)
- 优势:相比预测噪声,速度预测更稳定,采样步数更少
Inference
Step 1: 初始化
- 从高斯噪声 开始(T=1)
- 准备文本条件(和可选的图像条件)
Step 2: ODE 求解
- 使用 一阶欧拉法 迭代求解概率流 ODE:
- 重复调用 DiT 网络预测速度,逐步去噪
- 步数:通常 10-50 步即可(比 DDPM 快很多)
Step 3: 解码
- 得到干净的潜码 后,用 3D-VAE 解码器 重建为像素视频
Notes
- TAE:一般就是3D Conv或者1D+2D,以及再加一些temperal self-attention.对H,W,T同时下采样8倍。
- pachify:在H,W,T上同时下采样立方体。
- 3D position embedding:将传统2D图像的位置嵌入扩展为独立的时间、高度、宽度三个一维嵌入表:,每个token对应一个3D坐标 ,分别从三个嵌入表中查表,再逐元素相加得到最终位置编码
- text-encoder:同时用好几个encoder再concate,这是因为clip型的适合用于提取globally semantic feature,然后还需要一些文字级别的featrue(可以用ByT5)
- 直接在隐空间中进行flow matching
- 并非自回归结构,是同时对所有帧加噪去噪。这种方法是直观的,因为一段视频内部有着极其强烈的依赖,不只是语义上的依赖还有帧与帧之间的平滑过渡等,所以将整段视频同时生成是合理的。但是这显然也有很大的问题,无法有效扩展到无限长,无法实时交互,缺乏因果等都是问题
- 在推理时进行tiling,也就是把整个视频分块生成,块之间有一些overlapping进行线性融合避免伪影。
这两个工作作为视频生成来讲算是不错,但是和world model 之间的gap还非常明显,显然没有real-time interaction,用户的自由度还很低,生成的视频也很短,还没使用自回归架构,物理不一致也很多。
除了diffusion策略之外,自回归生成也是视频生成领域的一条主线。自回归的好处在于能够理论上无限制地扩展长度,并且允许交互。
Autoregressive-Based
借鉴于LLM,如GPT等的做法,引入自回归方法,通过将视频表示为token,预定义一个的可学习的“词表”进行生成。自回归范式主要分为:next-token,next-block,next-scale等等
Visual Tokenizer
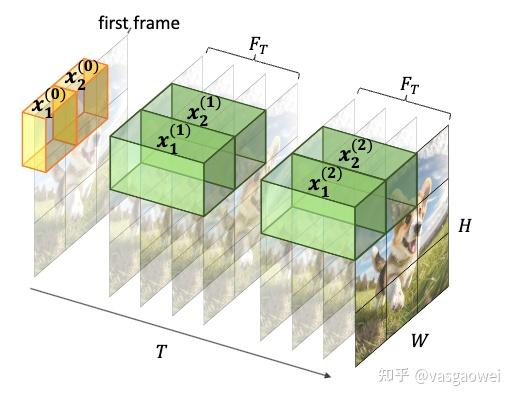 这是一个典型的spatio-temporal tokenizer。
这是一个典型的spatio-temporal tokenizer。
paradigm
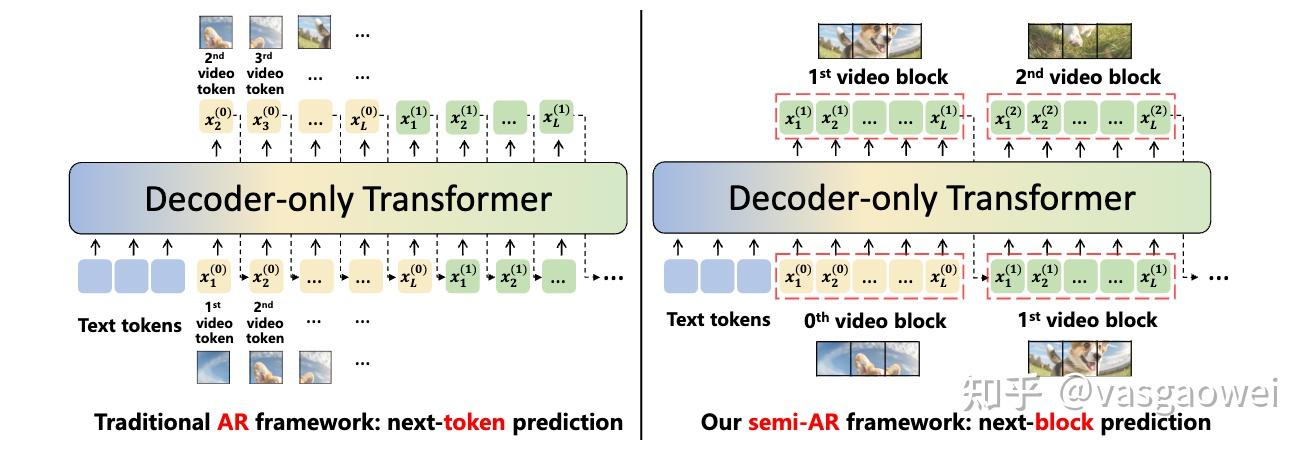
但是这又很明显有一个问题。建立一个类似于词表的视觉codebook我认为事实上并不太合理,因为视觉内容并不像语言一样可以被一个词表穷尽,强行量化只会导致质量上的损失。
折中方案
Next frame diffusion
这个工作用扩散的方式进行next-frame prediction,实现了交互性。交互性体现在“动作条件视频生成”。该模型以过去帧序列 和动作 为条件,并训练用于预测下一帧
Architecture
NFD 的架构包含一个将原始视觉信号变换为潜在表示的 tokenizer,以及一个生成这些潜在表示的 Diffusion Transformer。
- Tokenizer:为了实现帧级别与模型的交互,作者采用了一个图像级别的 tokenizer,将 每一帧转换为一系列潜在表示。对于动作,将相机角度量化为离散的区间(这后会看到这并没有那么好),并将其他动作分类为 7 个互斥的类别,每个类别由一个唯一的 token表示。
- 块级因果注意力机制:该机制结合了每帧内的双向注意力和跨帧的因果依赖关系,以高效地建模时空依赖。具体而言,对于每帧中的每个 token,它将关注同一帧内的所有 token(即帧内注意力),以及所有先前帧中的 token(即因果帧间注意力)。与计算密集型的 3D 全注意力机制相比,该方法50% 降低了总体成本,从而实现了硬件高效且流式地并行预测下一帧中的所有 token。
- 动作条件化。 作者利用一个线性层将动作映射为动作向量,并探索了多种 DiT 架构设计,以将动作条件化融入模型中。遵循 DiT 的方法,研究了三种条件化机制adaLN-zero 块、交叉注意力块和上下文条件化。作者采用 adaLN-zero 条件化,因为它在经验上表现出最佳性能。
- 三维位置嵌入。 遵循 HunyuanVideo,作者将查询和键 token 的头部维度分离为[nT , nH , nW ],独立编码它们的时间和空间对应关系。具体而言,分别计算每个轴的旋转频率嵌入,并沿最后一个维度将它们连结起来。
Training&Sampling
采用flow-matching,采用动作和前序帧进行引导。
接下来该工作还有很多其他的技巧和方法来进一步加速采样过程,以实现实时的交互。由于并非这篇blog的重点故而按下不表。但是采样速度再快也没有办法避免历史过长而缩减上下文窗口。
感觉这篇工作也是非常自然的想法,结合了扩散和自回归。而且离world model也更近了一步。
Diffusion forcing
这篇属于现在world model中比较常用的范式,是一个很solid的工作。
这个方法结合了自回归和diffusion的好处:
- 能够做引导(分类器引导)
- 避免长程崩坏(教会模型不要完全相信历史帧,即避免teacher forcing的坏处)
- 做结合(这个比较抽象,事实上就是:因为 full-sequence diffusion是将视频视为一个整体进行逆向扩散,生成的视频从头到尾都会和训练中拟合的数据分布中的某个样本点相似;而自回归是根据历史帧推测下一帧,所以生成的序列很有可能在中间某一处开始偏离原视频,开始拟合另一个视频,能将两者结合)
- 无限长视频生成(因为它将历史帧都储存在某个隐变量之中)。
核心概念:Per-Frame Noise Level
与传统扩散模型不同,Diffusion Forcing 为序列中每个 token(帧)分配独立的噪声水平,而非全序列共享同一噪声。这使得每帧可在不同去噪阶段,支持灵活的序列长度与流式生成。

训练过程
事实上整个训练过程的目的是:训练在带有任意噪声组合的历史帧条件下重构当前帧。
采样过程
Diffusion Forcing 的采样如 Algorithm 2 所示,其定义通过在二维网格 上规定噪声计划,其中:
- 网格表示为
- 每一列对应一个时间步 ,每一行由索引 决定噪声级别
- 表示时间步 的 token 在第 行上的期望噪声水平
为了生成长度为 的整个序列,初始化 token 序列 为白噪声,对应于最大噪声水平:然后逐行遍历网格,从左到右跨列进行降噪,直到每个 token 达到网格 所规定的噪声水平。
最终,当到达最底行 时,所有 token 已完全清洁,即其噪声水平为:
矩阵 K 指定了在序列扩散的每一步中每个token的降噪速度。由于DiffusionForcing被训练用于降噪所有噪声级别序列的token,K 可以灵活设计以实现不同行为,而无需重新训练模型。
World Model?
下面讨论一些本质上是条件视频生成的所谓世界模型。他们与上面介绍的视频生成模型不同的地方在于,能够在理论上自回归地无限扩展,能对输入的动作条件(视角转换,前进后退,放置)进行响应,并且提出了一些memory机制。
下一篇工作是腾讯的Voyager,能够根据图片输入和用户指定的相机轨迹来生成视频,并且进行3D重建,是一个新的Task。
Voyager
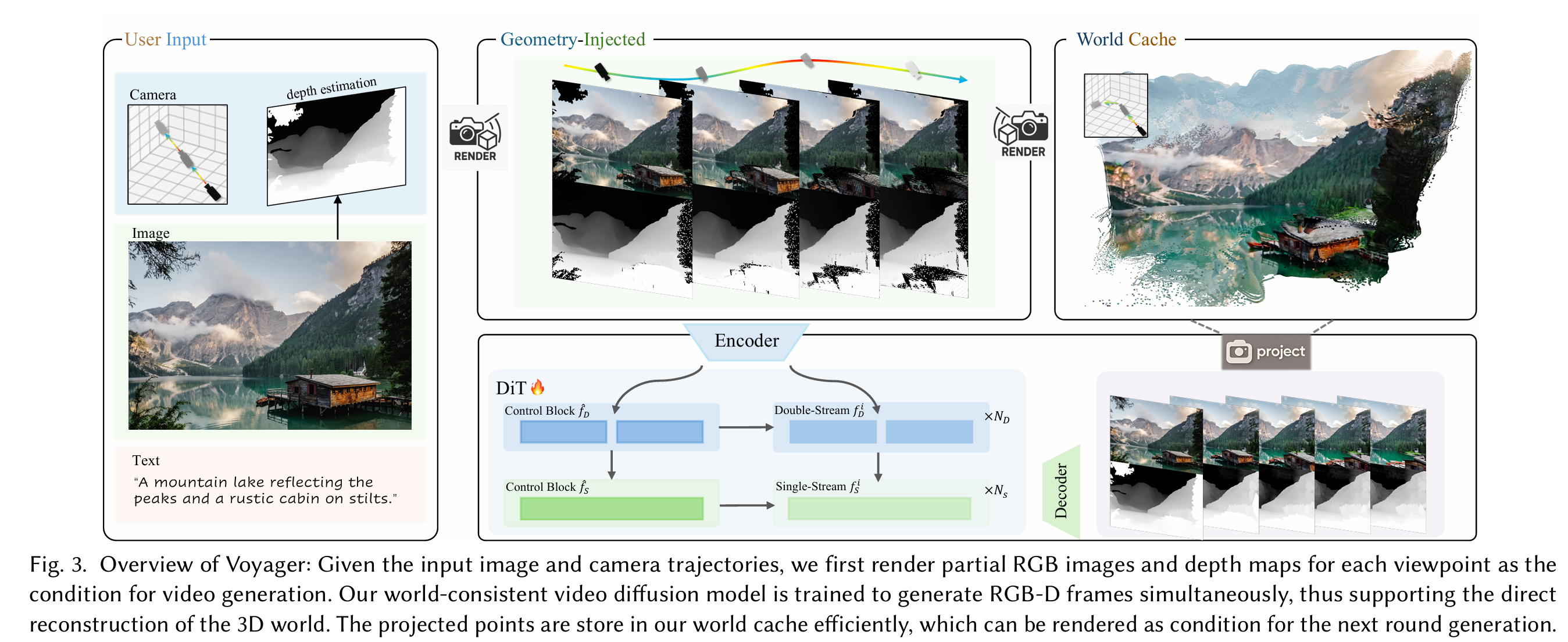 这篇主要是在做Camera-Controllable View Generation和 Long-Range Video Generation
这篇主要是在做Camera-Controllable View Generation和 Long-Range Video Generation
要实现更精确的控制就必然要加入更explicit的约束,这里主要是进行了对输入image进行点云的构建,后面根据不同的相机参数渲染rgb图和depth图进行显式的几何引导,并且通过每一帧的生成来实时更新点云。
并且对于远距离探索,这里采用了通过点云来进行世界缓存的机制,
世界缓存
“具体而言,我们以逐帧方式向缓存增量添加新点:给定先前帧累积的点云 ,我们从当前相机视角 渲染可见性掩码 。位于不可见区域的点优先加入。对于可见区域,若现有点的表面法向量与当前视角方向夹角超过 90 度,新点同样更新至缓存,因为这些现有点无法在当前视点被观测到。该策略使存储点数减少约 40%,并避免了多帧聚合导致的噪声累积。”
感觉要实现无限的扩展必须要保证所储存的“外部记忆”总量要在一个限度之内,我们也许可以只维护所见范围内的一小部分点云,再根据移动实时生成,但是这样又会造成很多重复的计算。个人感觉这不算太高明的方法。
长视频生成 这里是采用了有重叠的clip-wise生成,使clip之间平滑过渡具体来说:
(1)首先将输入视频划分为重叠片段,其中重叠区域长度为单片段长度的一半。每个片段的重叠区域使用前一片段的生成结果进行初始化,作为当片段重叠区域的噪声初始化。
(2)完成连续两个片段的推理后,对重叠区域进行均值融合,并向合并后的片段注入轻量级噪声。随后执行最终轮降噪处理以优化过渡效果。
数据集 voyager所用的数据集有两个,一个是Realestate,是一个video clip和camera pose相配套的数据集,另一个是DL3DV-10K这个是一个具有大量室外场景视频的数据集。
评估 评估所用的指标是生成的视频和ground truth算PSNR、SSIM和LPIPS。我认为这是个有待改进的地方,首先是从一张图片我们本来就不能完全预测出来其它视角的所有细节,和ground truth比较也许不是太合理。其次是这也许限制了模型的想象力和结果的多样性。
这个工作提供了一个insight是:将每一帧和其深度图拼在一起同时预测能提高预测的质量,这和VGGT将相机参数、深度图、关键点轨迹等同时预测能提高准确率一样。
WorldMem
这个工作本质上也是动作条件的视频生成,包含了前后移动,视角转移,放置物品等。
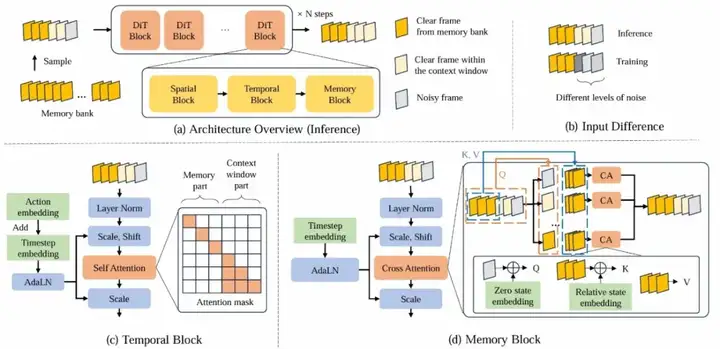
Memory Bank
这里实现时间一致性的方法是维护一个外部的memory bank,包含每个时间步的{记忆帧(图片),位姿,时间戳},通过一套手工定制的算法来筛选和待生成帧相关性最大的历史帧进行引导。