DDPM(likelihood-based)
参考- Understanding Diffusion Models: A Unified Perspective
这里省略了大量的数学推导,仅保留必要的数学表达式,以提高可读性
书接上回,我们可以认为variable diffusion model就是具有如下三条假设的HVAE:
潜在维度恰好等于数据维度
每个时间步的潜在编码器结构不是学成的;它是作为线性高斯模型预先定义的。换句话说,它是一个
以前一时间步输出为中心的高斯分布。
潜在编码器的高斯参数随时间变化,使得最终时间步T 的潜在分布为标准正态分布
编码器
编码器 显式地建模为:
q ( x t ∣ x t − 1 ) = N ( x t ; α t x t − 1 , ( 1 − α t ) I ) q\left(\boldsymbol{x}_{t} \mid \boldsymbol{x}_{t-1}\right)=\mathcal{N}\left(\boldsymbol{x}_{t} ; \sqrt{\alpha_{t}} \boldsymbol{x}_{t-1},\left(1-\alpha_{t}\right) \mathbf{I}\right) q ( x t ∣ x t − 1 ) = N ( x t ; α t x t − 1 , ( 1 − α t ) I )
编码器这样规定的目的是:当我们任意给定一个干净图像x 0 x_0 x 0 x T x_T x T
并且,它有一些十分良好的性质,当我们给定了α 1 , α 2 , … , α T \alpha_1,\alpha_2,\dots,\alpha_T α 1 , α 2 , … , α T q ( x t ∣ x 0 ) q(\boldsymbol{x}_t \mid \boldsymbol{x}_0) q ( x t ∣ x 0 ) q ( x t − 1 ∣ x t , x 0 ) q(\boldsymbol{x}_{t-1} \mid \boldsymbol{x}_t, \boldsymbol{x}_0) q ( x t − 1 ∣ x t , x 0 )
其中,q ( x t ∣ x 0 ) ∼ N ( α t ˉ x 0 , ( 1 − α t ˉ ) I ) , α t ˉ = ∏ i = 1 t α i q(\boldsymbol{x}_t\mid\boldsymbol{x}_0)\sim \mathcal{N}(\sqrt{\bar{\alpha_t}}\boldsymbol{x_0},(1-\bar{\alpha_t})\mathbf{I}),\bar{\alpha_t}=\prod_{i=1}^t\alpha_i q ( x t ∣ x 0 ) ∼ N ( α t ˉ x 0 , ( 1 − α t ˉ ) I ) , α t ˉ = ∏ i = 1 t α i
ELBO
我们通过最大似然估计来优化模型参数,具体来说是通过优化似然函数的下界(ELBO)来间接优化似然函数。
表达式为:
log p ( x 0 ) = ∫ log p ( x 0 : T ) d x 1 : T \log{p(x_0)}=\int \log{p(x_{0:T})} dx_{1:T} log p ( x 0 ) = ∫ log p ( x 0 : T ) d x 1 : T 这表示了任意干净图像x 0 x_0 x 0 x 0 x_0 x 0
ELBO为:
E q ( x 1 ∣ x 0 ) [ log p θ ( x 0 ∣ x 1 ) ] ⏟ reconstruction term − D K L ( q ( x T ∣ x 0 ) ∥ p ( x T ) ) ⏟ prior matching term − ∑ t = 2 T E q ( x t ∣ x 0 ) [ D K L ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) ] ⏟ denoising matching term \underbrace{\mathbb{E}_{q\left(\boldsymbol{x}_{1} \mid \boldsymbol{x}_{0}\right)}\left[\log p_{\theta}\left(\boldsymbol{x}_{0} \mid \boldsymbol{x}_{1}\right)\right]}_{\text {reconstruction term }}-\underbrace{D_{\mathrm{KL}}\left(q\left(\boldsymbol{x}_{T} \mid \boldsymbol{x}_{0}\right) \| p\left(\boldsymbol{x}_{T}\right)\right)}_{\text {prior matching term }}-\sum_{t=2}^{T} \underbrace{\mathbb{E}_{q\left(\boldsymbol{x}_{t} \mid \boldsymbol{x}_{0}\right)}\left[D_{\mathrm{KL}}\left(q\left(\boldsymbol{x}_{t-1} \mid \boldsymbol{x}_{t}, \boldsymbol{x}_{0}\right) \| p_{\theta}\left(\boldsymbol{x}_{t-1} \mid \boldsymbol{x}_{t}\right)\right)\right]}_{\text {denoising matching term }} reconstruction term E q ( x 1 ∣ x 0 ) [ log p θ ( x 0 ∣ x 1 ) ] − prior matching term D KL ( q ( x T ∣ x 0 ) ∥ p ( x T ) ) − t = 2 ∑ T denoising matching term E q ( x t ∣ x 0 ) [ D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) ]
E q ( x 1 ∣ x 0 ) [ log p θ ( x 0 ∣ x 1 ) ] \mathbb{E}_{q(\boldsymbol{x}_{1}|\boldsymbol{x}_{0})}\left[\log p_{\theta}(\boldsymbol{x}_{0}|\boldsymbol{x}_{1})\right] E q ( x 1 ∣ x 0 ) [ log p θ ( x 0 ∣ x 1 ) ]
D K L ( q ( x T ∣ x 0 ) ∥ p ( x T ) ) D_{\mathrm{KL}}(q(\boldsymbol{x}_{T}|\boldsymbol{x}_{0})\parallel p(\boldsymbol{x}_{T})) D KL ( q ( x T ∣ x 0 ) ∥ p ( x T ))
E q ( x t ∣ x 0 ) [ D K L ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) ] \mathbb{E}_{q(\boldsymbol{x}_{t}|\boldsymbol{x}_{0})}\left[D_{\mathrm{KL}}(q(\boldsymbol{x}_{t-1}|\boldsymbol{x}_{t},\boldsymbol{x}_{0})\parallel p_{\theta}(\boldsymbol{x}_{t-1}|\boldsymbol{x}_{t}))\right] E q ( x t ∣ x 0 ) [ D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t )) ] p θ ( x t − 1 ∣ x t ) p_{\theta}(\boldsymbol{x}_{t-1}|\boldsymbol{x}_{t}) p θ ( x t − 1 ∣ x t ) q ( x t − 1 ∣ x t , x 0 ) q(\boldsymbol{x}_{t-1}|\boldsymbol{x}_{t},\boldsymbol{x}_{0}) q ( x t − 1 ∣ x t , x 0 ) q ( x t − 1 ∣ x t , x 0 ) q(\boldsymbol{x}_{t-1}|\boldsymbol{x}_{t},\boldsymbol{x}_{0}) q ( x t − 1 ∣ x t , x 0 ) x 0 \boldsymbol{x}_{0} x 0
其中,第一项的计算和VAE中的差不多,第二项是没有训练参数且T足够大时为0,计算量主要是第三项。根据线性高斯模型的性质可知,q ( x t − 1 ∣ x t , x 0 ) q(\boldsymbol{x}_{t-1} \mid \boldsymbol{x}_t,\boldsymbol{x}_0) q ( x t − 1 ∣ x t , x 0 )
q ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; α t ( 1 − α ˉ t − 1 ) x t + α ˉ t − 1 ( 1 − α t ) x 0 1 − α ˉ t ⏟ μ q ( x t , x 0 ) , ( 1 − α t ) ( 1 − α ˉ t − 1 ) 1 − α ˉ t I ) q\left(\boldsymbol{x}_{t-1} \mid \boldsymbol{x}_t, \boldsymbol{x}_0\right) = \mathcal{N}\left(\boldsymbol{x}_{t-1}; \underbrace{\frac{\sqrt{\alpha_t}\left(1-\bar{\alpha}_{t-1}\right)\boldsymbol{x}_t + \sqrt{\bar{\alpha}_{t-1}}\left(1-\alpha_t\right)\boldsymbol{x}_0}{1-\bar{\alpha}_t}}_{\mu_q(\boldsymbol{x}_t, \boldsymbol{x}_0)}, \frac{\left(1-\alpha_t\right)\left(1-\bar{\alpha}_{t-1}\right)}{1-\bar{\alpha}_t}\mathbf{I}\right) q ( x t − 1 ∣ x t , x 0 ) = N x t − 1 ; μ q ( x t , x 0 ) 1 − α ˉ t α t ( 1 − α ˉ t − 1 ) x t + α ˉ t − 1 ( 1 − α t ) x 0 , 1 − α ˉ t ( 1 − α t ) ( 1 − α ˉ t − 1 ) I 由于协方差矩阵是常数且我们想要p θ ( x t − 1 ∣ x t ) p_\theta (\boldsymbol{x}_{t-1}\mid \boldsymbol{x}_t) p θ ( x t − 1 ∣ x t ) p θ ( x t − 1 ∣ x t ) p_\theta(\boldsymbol{x}_{t-1}\mid \boldsymbol{x}_t) p θ ( x t − 1 ∣ x t )
再代入正态分布KL散度的公式,最后的优化目标为:
∣ ∣ μ θ − μ q ∣ ∣ 2 2 ||\mu_\theta-\mu_q||_2^2 ∣∣ μ θ − μ q ∣ ∣ 2 2 即两者均值的L2距离的平方。
由于μ θ \mu_\theta μ θ x t \boldsymbol{x}_t x t t t t x 0 x_0 x 0 p θ p_\theta p θ μ q \mu_q μ q
μ θ ( x t , t ) = α t ( 1 − α ˉ t − 1 ) x t + α ˉ t − 1 ( 1 − α t ) x ^ θ ( x t , t ) 1 − α ˉ t \mu_{\theta}\left(\boldsymbol{x}_{t}, t\right)=\frac{\sqrt{\alpha_{t}}\left(1-\bar{\alpha}_{t-1}\right)\boldsymbol{x}_{t}+\sqrt{\bar{\alpha}_{t-1}}\left(1-\alpha_{t}\right)\hat{\boldsymbol{x}}_{\theta}\left(\boldsymbol{x}_{t}, t\right)}{1-\bar{\alpha}_{t}} μ θ ( x t , t ) = 1 − α ˉ t α t ( 1 − α ˉ t − 1 ) x t + α ˉ t − 1 ( 1 − α t ) x ^ θ ( x t , t ) 于是最后的的优化目标变成了
∥ x ^ θ ( x t , t ) − x 0 ∥ 2 2 \left\|\hat{\boldsymbol{x}}_{\theta}\left(\boldsymbol{x}_{t}, t\right)-\boldsymbol{x}_{0}\right\|_{2}^{2} ∥ x ^ θ ( x t , t ) − x 0 ∥ 2 2 因此,优化一个VDM归结为学习一个神经网络,从任意噪声化的版本中预测原始真实值图像。(为什么这个结论看起来是如此平凡🤣)此外,通过在所有噪声级别上最小化我们推导出的ELBO目标的第三项可以近似为在所有时间步上最小化期望(这是蒙特卡洛采样积分法,不得不说要不是有这种采样法,推导的这么一长串东西都完全没法算啊):
arg min θ E t ∼ U { 2 , T } [ E q ( x t ∣ x 0 ) [ D K L ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) ] ] \underset{\boldsymbol{\theta}}{\arg\min}\,\mathbb{E}_{t \sim U\{2,T\}}\left[\mathbb{E}_{q\left(\boldsymbol{x}_t \mid \boldsymbol{x}_0\right)}\left[D_{\mathrm{KL}}\left(q\left(\boldsymbol{x}_{t-1} \mid \boldsymbol{x}_t, \boldsymbol{x}_0\right) \parallel p_{\boldsymbol{\theta}}\left(\boldsymbol{x}_{t-1} \mid \boldsymbol{x}_t\right)\right)\right]\right] θ arg min E t ∼ U { 2 , T } [ E q ( x t ∣ x 0 ) [ D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) ] ] 然后可以使用随机样本在时间步上进行优化。
另外两种目标函数
而事实上这个目标函数还有另外两种等效的形式
第二种(ϵ \epsilon ϵ
首先,我们可以利用重参数化技巧。在推导 q ( x t ∣ x 0 ) q(\boldsymbol{x}_{t}|\boldsymbol{x}_{0}) q ( x t ∣ x 0 )
x 0 = x t − 1 − α ˉ t ϵ 0 α ˉ t \boldsymbol{x}_{0} = \frac{\boldsymbol{x}_{t} - \sqrt{1-\bar{\alpha}_{t}}\boldsymbol{\epsilon}_{0}}{\sqrt{\bar{\alpha}_{t}}} x 0 = α ˉ t x t − 1 − α ˉ t ϵ 0 于是μ q ( x t , x 0 ) \mu_q(\boldsymbol{x}_t,\boldsymbol{x}_0) μ q ( x t , x 0 )
μ q ( x t , x 0 ) = 1 α t x t − 1 − α t 1 − α ˉ t α t ϵ 0 \mu_q(\boldsymbol{x}_t,\boldsymbol{x}_0)=\frac{1}{\sqrt{\alpha_{t}}}\boldsymbol{x}_{t} - \frac{1-\alpha_{t}}{\sqrt{1-\bar{\alpha}_{t}}\sqrt{\alpha_{t}}}\boldsymbol{\epsilon}_{0} μ q ( x t , x 0 ) = α t 1 x t − 1 − α ˉ t α t 1 − α t ϵ 0 因此,我们可以将我们的近似降噪转移均值 μ θ ( x t , t ) \mu_{\theta}(\boldsymbol{x}_{t},t) μ θ ( x t , t )
μ θ ( x t , t ) = 1 α t x t − 1 − α t 1 − α ˉ t α t ϵ ^ θ ( x t , t ) \mu_{\theta}(\boldsymbol{x}_{t},t) = \frac{1}{\sqrt{\alpha_{t}}}\boldsymbol{x}_{t} - \frac{1-\alpha_{t}}{\sqrt{1-\bar{\alpha}_{t}}\sqrt{\alpha_{t}}}\hat{\boldsymbol{\epsilon}}_{\theta}(\boldsymbol{x}_{t},t) μ θ ( x t , t ) = α t 1 x t − 1 − α ˉ t α t 1 − α t ϵ ^ θ ( x t , t ) 并且相应的最优化问题变为:
arg min θ 1 2 σ q 2 ( t ) ( 1 − α t ) 2 ( 1 − α ˉ t ) α t [ ∥ ϵ 0 − ϵ ^ θ ( x t , t ) ∥ 2 2 ] \underset{\boldsymbol{\theta}}{\arg\min}\,\frac{1}{2\sigma_{q}^{2}(t)}\frac{\left(1-\alpha_{t}\right)^{2}}{\left(1-\bar{\alpha}_{t}\right)\alpha_{t}}\left[\left\|\boldsymbol{\epsilon}_{0}-\hat{\boldsymbol{\epsilon}}_{\theta}\left(\boldsymbol{x}_{t}, t\right)\right\|_{2}^{2}\right] θ arg min 2 σ q 2 ( t ) 1 ( 1 − α ˉ t ) α t ( 1 − α t ) 2 [ ∥ ϵ 0 − ϵ ^ θ ( x t , t ) ∥ 2 2 ] 在这里,ϵ ^ θ ( x t , t ) \hat{\bm{\epsilon}}_{\theta}(\bm{x}_{t}, t) ϵ ^ θ ( x t , t ) x t \bm{x}_{t} x t ϵ 0 ∼ N ( ϵ ; 0 , I ) \bm{\epsilon}_{0} \sim \mathcal{N}(\bm{\epsilon}; \mathbf{0}, \mathbf{I}) ϵ 0 ∼ N ( ϵ ; 0 , I ) x 0 \bm{x}_{0} x 0 x 0 \bm{x}_{0} x 0
这里也可以这样理解,任意时间步的图像都可以由原始图像一步加噪得到,我们只要用网络去预测加的那个噪声也可以达到同样的效果。并且也许预测噪声相当于resnet预测残差的想法,可能更容易拟合(?)故而效果更好。
而这实际上就是DDPM的做法。
第三种(v-prediction)
v-prediction 通常在方差保持 (Variance Preserving, VP) 的设定下最为直观,即假定前向加噪过程满足 α t 2 + σ t 2 = 1 \alpha_t^2 + \sigma_t^2 = 1 α t 2 + σ t 2 = 1 ϕ t ∈ [ 0 , π / 2 ] \phi_t \in [0, \pi/2] ϕ t ∈ [ 0 , π /2 ]
信号系数 : α t = cos ϕ t \alpha_t = \cos\phi_t α t = cos ϕ t 噪声系数 : σ t = sin ϕ t \sigma_t = \sin\phi_t σ t = sin ϕ t
当 t = 0 t=0 t = 0 ϕ t ≈ 0 \phi_t \approx 0 ϕ t ≈ 0 t → T t \to T t → T ϕ t ≈ π / 2 \phi_t \approx \pi/2 ϕ t ≈ π /2 x x x ϵ \epsilon ϵ z t = cos ϕ t ⋅ x + sin ϕ t ⋅ ϵ z_t = \cos\phi_t \cdot x + \sin\phi_t \cdot \epsilon z t = cos ϕ t ⋅ x + sin ϕ t ⋅ ϵ
定义 v (Velocity, 速度向量)
既然 z t z_t z t ϕ t \phi_t ϕ t 运动速度 (Velocity) 也就是对角度 ϕ t \phi_t ϕ t v t = ∂ z t ∂ ϕ t = ∂ ∂ ϕ t ( cos ϕ t ⋅ x + sin ϕ t ⋅ ϵ ) v_t = \frac{\partial z_t}{\partial \phi_t} = \frac{\partial}{\partial \phi_t}(\cos\phi_t \cdot x + \sin\phi_t \cdot \epsilon) v t = ∂ ϕ t ∂ z t = ∂ ϕ t ∂ ( cos ϕ t ⋅ x + sin ϕ t ⋅ ϵ ) v t = − sin ϕ t ⋅ x + cos ϕ t ⋅ ϵ v_t = -\sin\phi_t \cdot x + \cos\phi_t \cdot \epsilon v t = − sin ϕ t ⋅ x + cos ϕ t ⋅ ϵ
替换回 α t \alpha_t α t σ t \sigma_t σ t v t = α t ϵ − σ t x v_t = \alpha_t \epsilon - \sigma_t x v t = α t ϵ − σ t x (注意:z t z_t z t v t v_t v t z t ⋅ v t = 0 z_t \cdot v_t = 0 z t ⋅ v t = 0
写成矩阵的形式:
[ z t v t ] = [ cos ϕ t sin ϕ t − sin ϕ t cos ϕ t ] [ x ϵ ] \begin{bmatrix} z_t \\ v_t \end{bmatrix} = \begin{bmatrix} \cos\phi_t & \sin\phi_t \\ -\sin\phi_t & \cos\phi_t \end{bmatrix} \begin{bmatrix} x \\ \epsilon \end{bmatrix} [ z t v t ] = [ cos ϕ t − sin ϕ t sin ϕ t cos ϕ t ] [ x ϵ ]
你会发现,中间那个矩阵就是一个标准的二维旋转矩阵 R ( ϕ t ) R(\phi_t) R ( ϕ t ) !它代表把 ( x , ϵ ) (x, \epsilon) ( x , ϵ ) − ϕ t -\phi_t − ϕ t
而正交旋转矩阵的逆,就是它的转置。
所以,想要反解 x x x ϵ \epsilon ϵ
[ x ϵ ] = [ cos ϕ t − sin ϕ t sin ϕ t cos ϕ t ] [ z t v t ] \begin{bmatrix} x \\ \epsilon \end{bmatrix} = \begin{bmatrix} \cos\phi_t & -\sin\phi_t \\ \sin\phi_t & \cos\phi_t \end{bmatrix} \begin{bmatrix} z_t \\ v_t \end{bmatrix} [ x ϵ ] = [ cos ϕ t sin ϕ t − sin ϕ t cos ϕ t ] [ z t v t ]
直接展开,得到反解结果(对应图片中复杂的推导结论):
x = cos ϕ t ⋅ z t − sin ϕ t ⋅ v t x = \cos\phi_t \cdot z_t - \sin\phi_t \cdot v_t x = cos ϕ t ⋅ z t − sin ϕ t ⋅ v t ϵ = sin ϕ t ⋅ z t + cos ϕ t ⋅ v t \epsilon = \sin\phi_t \cdot z_t + \cos\phi_t \cdot v_t ϵ = sin ϕ t ⋅ z t + cos ϕ t ⋅ v t
接下来我们推导q ( z s ∣ z t , x ) , 0 < s < t < T q(z_s|z_t,x),0<s<t<T q ( z s ∣ z t , x ) , 0 < s < t < T
我们将刚才用神经网络预测出的 v ^ t \hat{v}_t v ^ t x ^ \hat{x} x ^ ϵ ^ \hat{\epsilon} ϵ ^ z s = cos ϕ s ( cos ϕ t ⋅ z t − sin ϕ t ⋅ v ^ t ) + sin ϕ s ( sin ϕ t ⋅ z t + cos ϕ t ⋅ v ^ t ) z_s = \cos\phi_s (\cos\phi_t \cdot z_t - \sin\phi_t \cdot \hat{v}_t) + \sin\phi_s (\sin\phi_t \cdot z_t + \cos\phi_t \cdot \hat{v}_t) z s = cos ϕ s ( cos ϕ t ⋅ z t − sin ϕ t ⋅ v ^ t ) + sin ϕ s ( sin ϕ t ⋅ z t + cos ϕ t ⋅ v ^ t )
接下来,把 z t z_t z t v ^ t \hat{v}_t v ^ t z s = ( cos ϕ s cos ϕ t + sin ϕ s sin ϕ t ) ⋅ z t + ( sin ϕ s cos ϕ t − cos ϕ s sin ϕ t ) ⋅ v ^ t z_s = (\cos\phi_s \cos\phi_t + \sin\phi_s \sin\phi_t) \cdot z_t + (\sin\phi_s \cos\phi_t - \cos\phi_s \sin\phi_t) \cdot \hat{v}_t z s = ( cos ϕ s cos ϕ t + sin ϕ s sin ϕ t ) ⋅ z t + ( sin ϕ s cos ϕ t − cos ϕ s sin ϕ t ) ⋅ v ^ t
利用两角差的余弦和正弦公式,瞬间得到最终极致简约的结果:
z s = cos ( ϕ s − ϕ t ) ⋅ z t + sin ( ϕ s − ϕ t ) ⋅ v ^ t z_s = \cos(\phi_s - \phi_t) \cdot z_t + \sin(\phi_s - \phi_t) \cdot \hat{v}_t z s = cos ( ϕ s − ϕ t ) ⋅ z t + sin ( ϕ s − ϕ t ) ⋅ v ^ t
于是我们的预测目标就变成了v.
通过上面的推导,你会发现 v-prediction 将扩散模型从“一维的加减噪声”变成了一个“在超球面上旋转 ”的问题(也就是图1那个四分之一圆弧的意思)。
前向加噪 :就是在 x x x ϵ \epsilon ϵ x x x v v v ϵ \epsilon ϵ 旋转 ϕ t \phi_t ϕ t z t z_t z t 网络预测 :模型不直接猜起点 x x x ϵ \epsilon ϵ z t z_t z t 切线运动方向(速度 v t v_t v t 。
score-based diffusion
Generative Modeling by Estimating Gradients of the Data Distribution
这是作者本人的博客,写得清晰易懂,并不需要有任何SDE基础,只要有基础概率论基础和懂一点点随机过程的概念即可。
事实上整个diffusion理论都被统一在了该SDE的框架之内,精妙绝伦。
条件生成
参考这个视频 ,现在主流的方法是classifier-free guidance,大概的想法就是:
在推理(生成)时,我们不需要任何外部分类器。对于同一个输入噪声,我们让这个统一的模型同时进行两次预测:
无条件预测:ε u n c o n d = m o d e l ( x t , ∅ ) ε_{uncond} = model(x_t, ∅) ε u n co n d = m o d e l ( x t , ∅ )
条件预测:ε c o n d = m o d e l ( x t , y ) ε_{cond} = model(x_t, y) ε co n d = m o d e l ( x t , y )
然后,我们计算两者的方向差,并将这个差值放大:
ε f i n a l = ε u n c o n d + s ∗ ( ε c o n d − ε u n c o n d ) ε_{final} = ε_{uncond} + s * (ε_{cond} - ε_{uncond}) ε f ina l = ε u n co n d + s ∗ ( ε co n d − ε u n co n d )
DDIM
参考苏神博客
DDIM是DDPM在的推广,DDPM通过定义p ( x t ∣ x t − 1 ) p(x_t|x_{t-1}) p ( x t ∣ x t − 1 ) p ( x t − 1 ∣ x t , x 0 ) = p ( x t ∣ x t − 1 , x 0 ) p ( x t − 1 ∣ x 0 ) p ( x t ∣ x 0 ) p(x_{t-1}|x_t,x_0)=\frac{p(x_{t}|x_{t-1},x_0)p(x_{t-1}|x_0)}{p(x_t|x_0)} p ( x t − 1 ∣ x t , x 0 ) = p ( x t ∣ x 0 ) p ( x t ∣ x t − 1 , x 0 ) p ( x t − 1 ∣ x 0 ) p ( x t ∣ x 0 ) , t = 1 , 2 , … , T p(x_t|x_0),t=1,2,\dots,T p ( x t ∣ x 0 ) , t = 1 , 2 , … , T p ( x t − 1 ∣ x t , x 0 ) = p ( x t − 1 ∣ x t ) p(x_{t-1}|x_t,x_0)=p(x_{t-1}|x_t) p ( x t − 1 ∣ x t , x 0 ) = p ( x t − 1 ∣ x t ) p ( x t − 1 ∣ x t , x 0 ) p(x_{t-1}|x_t,x_0) p ( x t − 1 ∣ x t , x 0 ) q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q ( x t − 1 ∣ x t , x 0 ) 可以 具备以下形式:
q ( x t − 1 ∣ x t , x 0 ) ∼ N ( x t − 1 ; β t − 1 2 − σ t 2 β ˉ t x t + ( α ˉ t − 1 − α ˉ t ⋅ β t − 1 2 − σ t 2 β ˉ t ) x 0 , σ t 2 I ) q(x_{t-1} \mid x_t, x_0) \sim \mathcal{N} \left(
x_{t-1};\
\frac{\sqrt{\beta_{t-1}^2 - \sigma_t^2}}{\bar{\beta}_t} x_t +
\left( \bar{\alpha}_{t-1} - \bar{\alpha}_t \cdot \frac{\sqrt{\beta_{t-1}^2 - \sigma_t^2}}{\bar{\beta}_t} \right) x_0,\
\sigma_t^2 \mathbf{I}
\right) q ( x t − 1 ∣ x t , x 0 ) ∼ N x t − 1 ; β ˉ t β t − 1 2 − σ t 2 x t + α ˉ t − 1 − α ˉ t ⋅ β ˉ t β t − 1 2 − σ t 2 x 0 , σ t 2 I 其中σ t \sigma_t σ t
进行上述改动后,事实上DDIM的训练算法和DDPM完全相同,区别只在采样。
而DDIM对于采样的加速取决于另一个观察:DDPM的训练结果实质上包含了它的任意子序列参数的训练结果。 因为DDPM训练的就是从任意时间步的噪声向量中预测原图,任意子序列的训练目标显然包含其中。
所以实际上DDPM也可以进行跳步采样,而DDIM在此基础上更进一步,通过改变σ t \sigma_t σ t
根据实验结果,应该是σ t \sigma_t σ t
下面给出σ t \sigma_t σ t
1. 选择时间步
从集合 {1, …, T} 中选择一个包含 N 个时间步的子序列
S = { s 1 , s 2 , . . . , s N } , s 1 = 1 , s N = T , s i < s i + 1 S = \{s_1, s_2, ..., s_N\}, \quad s_1 = 1, \; s_N = T, \; s_i < s_{i+1} S = { s 1 , s 2 , ... , s N } , s 1 = 1 , s N = T , s i < s i + 1 S = { t 0 , t 1 , . . . , t N } , t N = T , t 0 = 0 S = \{t_0, t_1, ..., t_N\}, \quad t_N = T, \; t_0 = 0 S = { t 0 , t 1 , ... , t N } , t N = T , t 0 = 0 2. 获取噪声预测模型
训练一个模型 ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵ θ ( x t , t ) ϵ \epsilon ϵ
x t = α t x 0 + 1 − α t ϵ , ϵ ∼ N ( 0 , I ) x_t = \sqrt{\alpha_t} \, x_0 + \sqrt{1 - \alpha_t} \, \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) x t = α t x 0 + 1 − α t ϵ , ϵ ∼ N ( 0 , I ) 3. 采样过程
x T ∼ N ( 0 , I ) x_T \sim \mathcal{N}(0, I) x T ∼ N ( 0 , I )
对于 i = N , . . . , 1 i = N, ..., 1 i = N , ... , 1
预测噪声
ϵ = ϵ θ ( x t i , t i ) \epsilon = \epsilon_\theta(x_{t_i}, t_i) ϵ = ϵ θ ( x t i , t i )
估计 x 0 x_0 x 0
x ^ 0 = x t i − 1 − α t i ϵ θ ( x t i , t i ) α t i \hat{x}_0 = \frac{x_{t_i} - \sqrt{1 - \alpha_{t_i}} \, \epsilon_\theta(x_{t_i}, t_i)}{\sqrt{\alpha_{t_i}}} x ^ 0 = α t i x t i − 1 − α t i ϵ θ ( x t i , t i )
计算 σ t \sigma_t σ t μ t \mu_t μ t α t \alpha_t α t
σ t = η ⋅ 1 − α t i − 1 1 − α t i ⋅ 1 − α t i α t i − 1 \sigma_t = \eta \cdot \sqrt{\frac{1 - \alpha_{t_{i-1}}}{1 - \alpha_{t_i}}} \cdot \sqrt{1 - \frac{\alpha_{t_i}}{\alpha_{t_{i-1}}}} σ t = η ⋅ 1 − α t i 1 − α t i − 1 ⋅ 1 − α t i − 1 α t i μ t = α t i − 1 x ^ 0 + 1 − α t i − 1 − σ t 2 ϵ θ ( x t i , t i ) \mu_t = \sqrt{\alpha_{t_{i-1}}} \, \hat{x}_0 + \sqrt{1 - \alpha_{t_{i-1}} - \sigma_t^2} \, \epsilon_\theta(x_{t_i}, t_i) μ t = α t i − 1 x ^ 0 + 1 − α t i − 1 − σ t 2 ϵ θ ( x t i , t i )
更新采样
x t i − 1 ∼ N ( μ t , σ t 2 ) x_{t_{i-1}} \sim \mathcal{N}(\mu_t, \sigma_t^2) x t i − 1 ∼ N ( μ t , σ t 2 ) (当设定 η = 0 \eta = 0 η = 0 σ t \sigma_t σ t
4. 输出
最终输出 x 0 x_0 x 0
说明
α t \alpha_t α t t t t ϵ θ \epsilon_\theta ϵ θ x ^ 0 \hat{x}_0 x ^ 0 σ t \sigma_t σ t μ t \mu_t μ t
DiT
用transformer架构替代了Unet,作为diffusion使用的架构。
Denoising Score Matching
1. 核心问题背景
在扩散模型框架下,分布对齐等价于在各个噪声水平 t t t
∇ x t log p fake ( x t , t ) ⟷ ∇ x t log p real ( x t , t ) \nabla_{x_t} \log p_{\text{fake}}(x_t, t) \longleftrightarrow \nabla_{x_t} \log p_{\text{real}}(x_t, t) ∇ x t log p fake ( x t , t ) ⟷ ∇ x t log p real ( x t , t ) 然而,边缘分布 p ( x t ) p(x_t) p ( x t )
p ( x t ) = ∫ p ( x t ∣ x 0 ) p ( x 0 ) d x 0 p(x_t) = \int p(x_t|x_0)p(x_0) dx_0 p ( x t ) = ∫ p ( x t ∣ x 0 ) p ( x 0 ) d x 0 直接对该积分求对数梯度在数学上是不可解的(Intractable)。为此,引入了 Denoising Score Matching (DSM) 的等价性结论。
2. 必备数学工具
在推导开始前,我们需要掌握两个核心数学技巧:
2.1 莱布尼茨积分规则 (Leibniz Rule)
在满足平滑性条件(如高斯分布)时,梯度算子可以与积分符号交换:
∇ x t ∫ p ( x t ∣ x 0 ) p ( x 0 ) d x 0 = ∫ ∇ x t p ( x t ∣ x 0 ) p ( x 0 ) d x 0 \nabla_{x_t} \int p(x_t | x_0) p(x_0) dx_0 = \int \nabla_{x_t} p(x_t | x_0) p(x_0) dx_0 ∇ x t ∫ p ( x t ∣ x 0 ) p ( x 0 ) d x 0 = ∫ ∇ x t p ( x t ∣ x 0 ) p ( x 0 ) d x 0 2.2 对数导数技巧 (Log-Derivative Trick)
根据复合函数链式法则,对于任何正值函数 f ( x ) f(x) f ( x )
∇ log f ( x ) = ∇ f ( x ) f ( x ) ⟹ ∇ f ( x ) = f ( x ) ∇ log f ( x ) \nabla \log f(x) = \frac{\nabla f(x)}{f(x)} \implies \nabla f(x) = f(x) \nabla \log f(x) ∇ log f ( x ) = f ( x ) ∇ f ( x ) ⟹ ∇ f ( x ) = f ( x ) ∇ log f ( x ) 该技巧常用于将梯度的积分转化为期望 的形式。
3. 关键引理:边缘分数是条件分数的期望
首先,我们要证明边缘分数本质上是所有可能原图 x 0 x_0 x 0
证明:
根据边缘分布定义,对其求梯度:
∇ x t p ( x t ) = ∫ ∇ x t p ( x t ∣ x 0 ) p ( x 0 ) d x 0 \nabla_{x_t} p(x_t) = \int \nabla_{x_t} p(x_t|x_0) p(x_0) dx_0 ∇ x t p ( x t ) = ∫ ∇ x t p ( x t ∣ x 0 ) p ( x 0 ) d x 0 应用对数导数技巧 :
∇ x t p ( x t ) = ∫ [ p ( x t ∣ x 0 ) ∇ x t log p ( x t ∣ x 0 ) ] p ( x 0 ) d x 0 \nabla_{x_t} p(x_t) = \int [p(x_t|x_0) \nabla_{x_t} \log p(x_t|x_0)] p(x_0) dx_0 ∇ x t p ( x t ) = ∫ [ p ( x t ∣ x 0 ) ∇ x t log p ( x t ∣ x 0 )] p ( x 0 ) d x 0 两边同时除以 p ( x t ) p(x_t) p ( x t )
∇ x t p ( x t ) p ( x t ) = ∫ ∇ x t log p ( x t ∣ x 0 ) p ( x t ∣ x 0 ) p ( x 0 ) p ( x t ) d x 0 \frac{\nabla_{x_t} p(x_t)}{p(x_t)} = \int \nabla_{x_t} \log p(x_t|x_0) \frac{p(x_t|x_0) p(x_0)}{p(x_t)} dx_0 p ( x t ) ∇ x t p ( x t ) = ∫ ∇ x t log p ( x t ∣ x 0 ) p ( x t ) p ( x t ∣ x 0 ) p ( x 0 ) d x 0 根据贝叶斯定理 p ( x 0 ∣ x t ) = p ( x t ∣ x 0 ) p ( x 0 ) p ( x t ) p(x_0|x_t) = \frac{p(x_t|x_0)p(x_0)}{p(x_t)} p ( x 0 ∣ x t ) = p ( x t ) p ( x t ∣ x 0 ) p ( x 0 )
∇ x t log p ( x t ) = ∫ ∇ x t log p ( x t ∣ x 0 ) p ( x 0 ∣ x t ) d x 0 = E p ( x 0 ∣ x t ) [ ∇ x t log p ( x t ∣ x 0 ) ] \nabla_{x_t} \log p(x_t) = \int \nabla_{x_t} \log p(x_t|x_0) p(x_0|x_t) dx_0 = \mathbb{E}_{p(x_0|x_t)} [\nabla_{x_t} \log p(x_t|x_0)] ∇ x t log p ( x t ) = ∫ ∇ x t log p ( x t ∣ x 0 ) p ( x 0 ∣ x t ) d x 0 = E p ( x 0 ∣ x t ) [ ∇ x t log p ( x t ∣ x 0 )] 结论:边缘分数等于条件分数的后验期望。
4. Score Matching 目标的等价性证明
我们要对比两个目标函数:
Score Matching (SM): 直接匹配边缘分数。
J S M ( θ ) = E p ( x t ) [ 1 2 ∥ s θ ( x t ) − ∇ x t log p ( x t ) ∥ 2 ] J_{SM}(\theta) = \mathbb{E}_{p(x_t)} \left[ \frac{1}{2} \| s_\theta(x_t) - \nabla_{x_t} \log p(x_t) \|^2 \right] J SM ( θ ) = E p ( x t ) [ 2 1 ∥ s θ ( x t ) − ∇ x t log p ( x t ) ∥ 2 ]
Denoising Score Matching (DSM): 匹配条件分数(DMD 实际采用的)。
J D S M ( θ ) = E p ( x 0 , x t ) [ 1 2 ∥ s θ ( x t ) − ∇ x t log p ( x t ∣ x 0 ) ∥ 2 ] J_{DSM}(\theta) = \mathbb{E}_{p(x_0, x_t)} \left[ \frac{1}{2} \| s_\theta(x_t) - \nabla_{x_t} \log p(x_t|x_0) \|^2 \right] J D SM ( θ ) = E p ( x 0 , x t ) [ 2 1 ∥ s θ ( x t ) − ∇ x t log p ( x t ∣ x 0 ) ∥ 2 ]
推导过程:
利用全期望公式 E p ( x 0 , x t ) [ ⋅ ] = E p ( x t ) [ E p ( x 0 ∣ x t ) [ ⋅ ] ] \mathbb{E}_{p(x_0, x_t)}[\cdot] = \mathbb{E}_{p(x_t)}[\mathbb{E}_{p(x_0|x_t)}[\cdot]] E p ( x 0 , x t ) [ ⋅ ] = E p ( x t ) [ E p ( x 0 ∣ x t ) [ ⋅ ]] J D S M J_{DSM} J D SM
J D S M ( θ ) = E p ( x t ) E p ( x 0 ∣ x t ) [ 1 2 ∥ s θ ( x t ) ∥ 2 − s θ ( x t ) ⋅ ∇ x t log p ( x t ∣ x 0 ) + 1 2 ∥ ∇ x t log p ( x t ∣ x 0 ) ∥ 2 ] J_{DSM}(\theta) = \mathbb{E}_{p(x_t)} \mathbb{E}_{p(x_0|x_t)} \left[ \frac{1}{2} \| s_\theta(x_t) \|^2 - s_\theta(x_t) \cdot \nabla_{x_t} \log p(x_t|x_0) + \frac{1}{2} \| \nabla_{x_t} \log p(x_t|x_0) \|^2 \right] J D SM ( θ ) = E p ( x t ) E p ( x 0 ∣ x t ) [ 2 1 ∥ s θ ( x t ) ∥ 2 − s θ ( x t ) ⋅ ∇ x t log p ( x t ∣ x 0 ) + 2 1 ∥ ∇ x t log p ( x t ∣ x 0 ) ∥ 2 ] 将内部期望 E p ( x 0 ∣ x t ) \mathbb{E}_{p(x_0|x_t)} E p ( x 0 ∣ x t )
第一项 :1 2 ∥ s θ ( x t ) ∥ 2 \frac{1}{2} \| s_\theta(x_t) \|^2 2 1 ∥ s θ ( x t ) ∥ 2 x 0 x_0 x 0 第二项 :− s θ ( x t ) ⋅ E p ( x 0 ∣ x t ) [ ∇ x t log p ( x t ∣ x 0 ) ] - s_\theta(x_t) \cdot \mathbb{E}_{p(x_0|x_t)} [\nabla_{x_t} \log p(x_t|x_0)] − s θ ( x t ) ⋅ E p ( x 0 ∣ x t ) [ ∇ x t log p ( x t ∣ x 0 )] − s θ ( x t ) ⋅ ∇ x t log p ( x t ) - s_\theta(x_t) \cdot \nabla_{x_t} \log p(x_t) − s θ ( x t ) ⋅ ∇ x t log p ( x t ) 第三项 :与参数 θ \theta θ C C C
整合后得到:
J D S M ( θ ) = E p ( x t ) [ 1 2 ∥ s θ ( x t ) ∥ 2 − s θ ( x t ) ⋅ ∇ x t log p ( x t ) ] + C J_{DSM}(\theta) = \mathbb{E}_{p(x_t)} \left[ \frac{1}{2} \| s_\theta(x_t) \|^2 - s_\theta(x_t) \cdot \nabla_{x_t} \log p(x_t) \right] + C J D SM ( θ ) = E p ( x t ) [ 2 1 ∥ s θ ( x t ) ∥ 2 − s θ ( x t ) ⋅ ∇ x t log p ( x t ) ] + C 对比 J S M J_{SM} J SM
J S M ( θ ) = E p ( x t ) [ 1 2 ∥ s θ ( x t ) ∥ 2 − s θ ( x t ) ⋅ ∇ x t log p ( x t ) + const ] J_{SM}(\theta) = \mathbb{E}_{p(x_t)} \left[ \frac{1}{2} \| s_\theta(x_t) \|^2 - s_\theta(x_t) \cdot \nabla_{x_t} \log p(x_t) + \text{const} \right] J SM ( θ ) = E p ( x t ) [ 2 1 ∥ s θ ( x t ) ∥ 2 − s θ ( x t ) ⋅ ∇ x t log p ( x t ) + const ] 结论:
J D S M ( θ ) = J S M ( θ ) + Const J_{DSM}(\theta) = J_{SM}(\theta) + \text{Const} J D SM ( θ ) = J SM ( θ ) + Const 这意味着两者的梯度 ∇ θ \nabla_\theta ∇ θ 优化易于计算的条件分数目标,在统计期望上完全等价于优化复杂的边缘分布目标。
5. 总结与直观理解
蒙特卡洛积分的视角 :直接计算边缘分布需要对全局进行积分。通过转化为条件分数目标,我们实际上是在进行蒙特卡洛采样——每次采样一个样本对 ( x 0 , x t ) (x_0, x_t) ( x 0 , x t ) DMD 的工程实现 :在 DMD 中,由于 p ( x t ∣ x 0 ) p(x_t|x_0) p ( x t ∣ x 0 ) ∇ x t log p ( x t ∣ x 0 ) \nabla_{x_t} \log p(x_t|x_0) ∇ x t log p ( x t ∣ x 0 ) − ϵ σ t -\frac{\epsilon}{\sigma_t} − σ t ϵ
通过这一数学证明,我们不仅确认了 DMD 损失函数的合理性,也深刻理解了扩散模型为何能通过“去噪”这一简单任务,最终学会生成复杂的真实分布。
Latent Diffusion Model
至此,我们从VAE来又回到了VAE,但是此VAE又不复当年。
为了减少计算量,将diffusion过程从像素空间搬到一个潜空间中。这里的潜空间选用vae的潜空间。
注意,这里的vae与原始的vae有一些不同。
原始的VAE没有那么多各种各样的重建损失,还被KL压缩得太狠,损失掉信息,并且明明潜空间不是高斯还非要按高斯来采样,自然不行。
LDM中的VAE更加重视重建,对潜空间本身没有太多要求,只约束方差不要太大,更像是一种AE(当然并非是一一对应的那种)。
之前直接把潜空间当高斯分布来采样当然不行,而现在我们有了diffusion以后就能很从容地从高斯出发采样潜空间了。
Noise Schedule
一、 离散马尔科夫转移到连续 SDE 的等价性证明
在 Score-based 视角中,连续时间 t ∈ [ 0 , 1 ] t \in [0, 1] t ∈ [ 0 , 1 ] N → ∞ N \to \infty N → ∞ d x = f ( x , t ) d t + g ( t ) d w dx = f(x, t)dt + g(t)dw d x = f ( x , t ) d t + g ( t ) d w f ( x , t ) f(x, t) f ( x , t ) g ( t ) g(t) g ( t ) d w dw d w
我们可以通过 Euler-Maruyama 离散化 结合 泰勒展开 来证明离散马尔科夫链与连续 SDE 的等价性。设定时间步长 Δ t = 1 / N \Delta t = 1/N Δ t = 1/ N
1. Variance Preserving (VP SDE) —— DDPM
离散马尔科夫转移(DDPM) :
x i = 1 − β i x i − 1 + β i z i , z i ∼ N ( 0 , I ) x_i = \sqrt{1 - \beta_i} x_{i-1} + \sqrt{\beta_i} z_i, \quad z_i \sim \mathcal{N}(0, I) x i = 1 − β i x i − 1 + β i z i , z i ∼ N ( 0 , I )
推导过程 :
令离散的噪声参数 β i \beta_i β i β ( t ) \beta(t) β ( t ) β i = β ( t i ) Δ t \beta_i = \beta(t_i)\Delta t β i = β ( t i ) Δ t Δ t → 0 \Delta t \to 0 Δ t → 0 1 − β i \sqrt{1 - \beta_i} 1 − β i 1 − β i = 1 − β ( t i ) Δ t ≈ 1 − 1 2 β ( t i ) Δ t \sqrt{1 - \beta_i} = \sqrt{1 - \beta(t_i)\Delta t} \approx 1 - \frac{1}{2}\beta(t_i)\Delta t 1 − β i = 1 − β ( t i ) Δ t ≈ 1 − 2 1 β ( t i ) Δ t
代入原式计算增量 x i − x i − 1 x_i - x_{i-1} x i − x i − 1 x i − x i − 1 ≈ ( 1 − 1 2 β ( t i ) Δ t ) x i − 1 − x i − 1 + β ( t i ) Δ t z i x_i - x_{i-1} \approx \left(1 - \frac{1}{2}\beta(t_i)\Delta t\right)x_{i-1} - x_{i-1} + \sqrt{\beta(t_i)\Delta t} z_i x i − x i − 1 ≈ ( 1 − 2 1 β ( t i ) Δ t ) x i − 1 − x i − 1 + β ( t i ) Δ t z i x i − x i − 1 ≈ − 1 2 β ( t i ) x i − 1 Δ t + β ( t i ) Δ t z i x_i - x_{i-1} \approx -\frac{1}{2}\beta(t_i)x_{i-1}\Delta t + \sqrt{\beta(t_i)}\sqrt{\Delta t} z_i x i − x i − 1 ≈ − 2 1 β ( t i ) x i − 1 Δ t + β ( t i ) Δ t z i
在极限 Δ t → 0 \Delta t \to 0 Δ t → 0 x i − x i − 1 → d x x_i - x_{i-1} \to dx x i − x i − 1 → d x Δ t → d t \Delta t \to dt Δ t → d t Δ t z i → d w \sqrt{\Delta t} z_i \to dw Δ t z i → d w 连续 SDE :
d x = − 1 2 β ( t ) x d t + β ( t ) d w dx = -\frac{1}{2}\beta(t)x dt + \sqrt{\beta(t)} dw d x = − 2 1 β ( t ) x d t + β ( t ) d w Q:什么是VP?(方差保持)
A:在加噪的每一步中,整个图像数据的边缘分布的方差(Magnitude / Scale)被保持住了。
让我们用最简单的数学来看。扩散模型的前向过程公式是:
z t = α t x + σ t ϵ z_t = \alpha_t x + \sigma_t \epsilon z t = α t x + σ t ϵ
在把图像 x x x 把图像像素值归一化到 [ − 1 , 1 ] [-1, 1] [ − 1 , 1 ] 。
这意味着,在宏观统计上,我们可以假设初始真实数据 x x x 方差为 1 ,即 V a r ( x ) = 1 Var(x) = 1 Va r ( x ) = 1 ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ϵ ∼ N ( 0 , I ) 方差也是 1 ,即 V a r ( ϵ ) = 1 Var(\epsilon) = 1 Va r ( ϵ ) = 1
现在,我们来计算一下 t t t z t z_t z t x x x ϵ \epsilon ϵ V a r ( z t ) = V a r ( α t x + σ t ϵ ) Var(z_t) = Var(\alpha_t x + \sigma_t \epsilon) Va r ( z t ) = Va r ( α t x + σ t ϵ ) V a r ( z t ) = α t 2 V a r ( x ) + σ t 2 V a r ( ϵ ) Var(z_t) = \alpha_t^2 Var(x) + \sigma_t^2 Var(\epsilon) Va r ( z t ) = α t 2 Va r ( x ) + σ t 2 Va r ( ϵ ) V a r ( z t ) = α t 2 ⋅ 1 + σ t 2 ⋅ 1 = α t 2 + σ t 2 Var(z_t) = \alpha_t^2 \cdot 1 + \sigma_t^2 \cdot 1 = \alpha_t^2 + \sigma_t^2 Va r ( z t ) = α t 2 ⋅ 1 + σ t 2 ⋅ 1 = α t 2 + σ t 2
“方差保持”的本质就在这里:
我们希望无论加噪到了哪一步(无论是 t = 1 t=1 t = 1 t = 1000 t=1000 t = 1000 z t z_t z t 始终维持在 1 不变 。
为了让 V a r ( z t ) ≡ 1 Var(z_t) \equiv 1 Va r ( z t ) ≡ 1 必须强行设计一个规则(约束条件) :
α t 2 + σ t 2 = 1 \alpha_t^2 + \sigma_t^2 = 1 α t 2 + σ t 2 = 1
Q: 为什么要强行保持方差为 1?
A:神经网络极其讨厌方差剧烈变化的输入。
如果不管方差,随着不断加噪声,图片的数值范围会变得越来越大。
U-Net 在 t = 1 t=1 t = 1 t = 1000 t=1000 t = 1000
VP 的意义在于 :它保证了 U-Net 在任何时刻接收到的输入张量(Tensor),其数值尺度(Scale)永远是稳定的 N ( 0 , I ) \mathcal{N}(0, I) N ( 0 , I )
2. Variance Exploding (VE SDE)
离散马尔科夫转移(SMLD) :
x i = x i − 1 + σ i 2 − σ i − 1 2 z i , z i ∼ N ( 0 , I ) x_i = x_{i-1} + \sqrt{\sigma_i^2 - \sigma_{i-1}^2} z_i, \quad z_i \sim \mathcal{N}(0, I) x i = x i − 1 + σ i 2 − σ i − 1 2 z i , z i ∼ N ( 0 , I )
推导过程 :
在这里,数据没有衰减项(x i − 1 x_{i-1} x i − 1 σ i 2 − σ i − 1 2 ≈ d [ σ 2 ( t ) ] d t Δ t \sigma_i^2 - \sigma_{i-1}^2 \approx \frac{d[\sigma^2(t)]}{dt} \Delta t σ i 2 − σ i − 1 2 ≈ d t d [ σ 2 ( t )] Δ t x i − x i − 1 x_i - x_{i-1} x i − x i − 1 x i − x i − 1 = d [ σ 2 ( t ) ] d t Δ t z i = d [ σ 2 ( t ) ] d t Δ t z i x_i - x_{i-1} = \sqrt{\frac{d[\sigma^2(t)]}{dt} \Delta t} z_i = \sqrt{\frac{d[\sigma^2(t)]}{dt}} \sqrt{\Delta t} z_i x i − x i − 1 = d t d [ σ 2 ( t )] Δ t z i = d t d [ σ 2 ( t )] Δ t z i
同样取极限 Δ t → 0 \Delta t \to 0 Δ t → 0 连续 SDE :
d x = d [ σ 2 ( t ) ] d t d w dx = \sqrt{\frac{d[\sigma^2(t)]}{dt}} dw d x = d t d [ σ 2 ( t )] d w
3. sub-VP SDE
Yang Song 在论文中提出了一种方差比 VP 更小的变体。其马尔科夫转移并非从历史模型中继承,而是直接为了在连续时间中约束方差而设计的。
连续 SDE :
d x = − 1 2 β ( t ) x d t + β ( t ) ( 1 − e − 2 ∫ 0 t β ( s ) d s ) d w dx = -\frac{1}{2}\beta(t)x dt + \sqrt{\beta(t)(1 - e^{-2\int_0^t \beta(s)ds})} dw d x = − 2 1 β ( t ) x d t + β ( t ) ( 1 − e − 2 ∫ 0 t β ( s ) d s ) d w
二、 三种调度的核心机制与优势
为了理解它们“好在哪”,我们需要看它们随着时间 t t t 边缘分布 q ( x t ∣ x 0 ) q(x_t | x_0) q ( x t ∣ x 0 ) 的方差表现。
调度方案 边缘分布方差 Var [ x t ∣ x 0 ] \text{Var}[x_t \vert x_0] Var [ x t ∣ x 0 ] 优势与核心亮点 VE SDE σ 2 ( t ) I \sigma^2(t)I σ 2 ( t ) I 方差爆炸,保持尺度 :模型不改变原始数据的均值尺度(只加噪不收缩)。在处理高维空间(如高分辨率图像、3D点云)时,数学形式极其简单,非常适合基于 Score Matching 的网络去学习不同尺度下的分数。VP SDE ( 1 − e − ∫ 0 t β ( s ) d s ) I (1 - e^{-\int_0^t \beta(s)ds})I ( 1 − e − ∫ 0 t β ( s ) d s ) I 方差守恒,极限稳定 :由于 − 1 2 β ( t ) x -\frac{1}{2}\beta(t)x − 2 1 β ( t ) x t → ∞ t \to \infty t → ∞ 1 1 1 sub-VP SDE ( 1 − e − ∫ 0 t β ( s ) d s ) 2 I (1 - e^{-\int_0^t \beta(s)ds})^2 I ( 1 − e − ∫ 0 t β ( s ) d s ) 2 I 方差更小,更高似然 :这是论文作者通过数学推导出的特例。它的方差在任何时刻都严格小于 VP SDE。好在哪 :在精确估计似然度(Likelihood)和计算 BPD(Bits Per Dimension)跑分时,由于随机游走的方差被进一步压扁,前向和反向过程的轨迹更加确定,通常能得到目前这三种里最好的理论似然度得分。
三、 究竟满足怎样的标准才算一个“好”的噪声调度?
评价一个噪声调度方案好坏,本质上是在评价它构建数据与噪声之间桥梁(信噪比演化轨迹)的质量 。在数学和工程上,一个完美的调度需要满足以下四大标准:
信噪比 (SNR) 边界的极致覆盖
初始状态 (t = 0 t=0 t = 0 :SNR 必须趋近于 ∞ \infty ∞ t = 0 t=0 t = 0 终结状态 (t = 1 t=1 t = 1 :SNR 必须趋近于 0 0 0 N ( 0 , I ) \mathcal{N}(0, I) N ( 0 , I )
中间状态的信息流失平滑度 (Smooth Information Destruction)
在加噪的中间过程,信号不能消失得太快,也不能太慢。如果破坏太快(像线性的 VP 调度在后期),模型绝大多数时间都在对着纯噪声“瞎猜”;如果像 Cosine Schedule 一样让信噪比线性下降,网络在每一个时间步都能获得稳定且有效的分数匹配(Score Matching)梯度。
网络学习的难易度 (Optimal Target Variance)
好的调度应当使得目标函数的方差在整个时间步上尽可能平稳。如 Karras 在 EDM 中指出的,如果 σ t \sigma_t σ t
易于计算和求解 ODE (Tractability)
它必须能推导出解析的 q ( x t ∣ x 0 ) q(x_t | x_0) q ( x t ∣ x 0 )
从宏观(物理和流形)的角度来看,我们真正关心的确实是边缘分布 q ( x t ) q(x_t) q ( x t ) 因为正是 q ( x t ) q(x_t) q ( x t ) p d a t a ( x ) p_{data}(x) p d a t a ( x ) N ( 0 , I ) \mathcal{N}(0, I) N ( 0 , I )
但在数学推导、模型训练和调度设计 的微观视角中,我们绝口不提(或者说尽量避开) q ( x t ) q(x_t) q ( x t ) q ( x t ∣ x 0 ) q(x_t|x_0) q ( x t ∣ x 0 )
为什么会产生这种反差?核心原因可以归结为以下三点:
1. 现实的无奈:q ( x t ) q(x_t) q ( x t )
根据全概率公式,q ( x t ) q(x_t) q ( x t ) q ( x t ) = ∫ q ( x t ∣ x 0 ) p d a t a ( x 0 ) d x 0 q(x_t) = \int q(x_t|x_0) p_{data}(x_0) dx_0 q ( x t ) = ∫ q ( x t ∣ x 0 ) p d a t a ( x 0 ) d x 0
这里的致命问题是:我们根本不知道真实的数据分布 p d a t a ( x 0 ) p_{data}(x_0) p d a t a ( x 0 )
自然界中所有猫的图片、所有高分辨率的 3D 点云,它们的分布解析式是未知的(这也是我们为什么要训练生成模型的原因)。因为 p d a t a ( x 0 ) p_{data}(x_0) p d a t a ( x 0 )
如果 q ( x t ) q(x_t) q ( x t ) t t t 分数 (Score) ∇ x t log q ( x t ) \nabla_{x_t} \log q(x_t) ∇ x t log q ( x t ) s θ ( x t , t ) s_\theta(x_t, t) s θ ( x t , t )
2. 破局的关键:Denoising Score Matching (去噪分数匹配) 的魔法
2011年,Pascal Vincent 提出了去噪分数匹配(后来被 Yang Song 完美融合到 SDE 框架中)。这是一个堪称“魔法”的数学等价定理:
“拟合未知的边缘分布分数 ∇ x t log q ( x t ) \nabla_{x_t} \log q(x_t) ∇ x t log q ( x t ) ∇ x t log q ( x t ∣ x 0 ) \nabla_{x_t} \log q(x_t|x_0) ∇ x t log q ( x t ∣ x 0 )
由于 q ( x t ∣ x 0 ) q(x_t|x_0) q ( x t ∣ x 0 ) N ( μ ( x 0 , t ) , σ 2 ( t ) I ) \mathcal{N}(\mu(x_0, t), \sigma^2(t)I) N ( μ ( x 0 , t ) , σ 2 ( t ) I ) ∇ x t log q ( x t ∣ x 0 ) = − x t − μ ( x 0 , t ) σ 2 ( t ) = − ϵ σ ( t ) \nabla_{x_t} \log q(x_t|x_0) = -\frac{x_t - \mu(x_0, t)}{\sigma^2(t)} = -\frac{\epsilon}{\sigma(t)} ∇ x t log q ( x t ∣ x 0 ) = − σ 2 ( t ) x t − μ ( x 0 , t ) = − σ ( t ) ϵ
结论: 我们之所以只盯着 q ( x t ∣ x 0 ) q(x_t|x_0) q ( x t ∣ x 0 ) 它是我们在整个系统里唯一能写出解析式、唯一能精确计算、并直接作为神经网络 Loss 目标的东西 。
3. 为什么要特别关注 q ( x t ∣ x 0 ) q(x_t|x_0) q ( x t ∣ x 0 )
如果你仔细看上面那个分数的解析式 ∇ x t log q ( x t ∣ x 0 ) = − ϵ σ ( t ) \nabla_{x_t} \log q(x_t|x_0) = -\frac{\epsilon}{\sigma(t)} ∇ x t log q ( x t ∣ x 0 ) = − σ ( t ) ϵ q ( x t ∣ x 0 ) q(x_t|x_0) q ( x t ∣ x 0 ) σ ( t ) \sigma(t) σ ( t )
我们极其关注方差 σ 2 ( t ) \sigma^2(t) σ 2 ( t )
方差定义了信噪比 (SNR): x t x_t x t σ 2 ( t ) \sigma^2(t) σ 2 ( t ) t t t 方差控制了神经网络的学习难度:
如果方差增长太快(例如一上来就加满噪声),网络在 t = 0.1 t=0.1 t = 0.1
如果方差增长太慢,网络大部分时间都在做极其简单的微小去噪任务,不仅浪费算力,而且到了最后时刻 T T T
保证 q ( x T ) q(x_T) q ( x T ) 我们虽然算不出 q ( x t ) q(x_t) q ( x t ) 必须保证 终局的 q ( x T ) ≈ N ( 0 , I ) q(x_T) \approx \mathcal{N}(0, I) q ( x T ) ≈ N ( 0 , I ) q ( x T ∣ x 0 ) q(x_T|x_0) q ( x T ∣ x 0 ) x 0 x_0 x 0 q ( x T ) q(x_T) q ( x T )
这是一个非常务实的问题!既然咱们不谈纯理论,那我们就直接从工业界(如 OpenAI, NVIDIA, Stability AI)的实际工程经验 出发,来看看在真实的代码和模型中,究竟哪种更好,以及大家都在用什么“具体参数和配方”。
先给出直接的结论:没有绝对的谁比谁好,但 VP 赢得了“古典时代”,EDM 统一了标准,而现在的“当红炸子鸡”是 Flow Matching(本质上是一种全新的调度)。
早期的赢家是 VP (方差保持) :因为 VP 在加噪过程中强行把方差缩放到 1,这让神经网络的输入数值范围始终稳定在 [ − 1 , 1 ] [-1, 1] [ − 1 , 1 ] 极大地避免了梯度爆炸和数值溢出 。早期的 Stable Diffusion (1.4/1.5) 和 Midjourney 都是基于 VP 的。VE (方差爆炸) 的工程痛点 :VE 的方差会一直涨到几百甚至上千,这在写代码时对神经网络的 LayerNorm 和权重初始化极度不友好。后来的大一统 (EDM) :NVIDIA 的 Karras 证明,只要你在网络输入前做一次**“缩放预处理 (Pre-conditioning)”**,VE 和 VP 效果一模一样。
下面是目前工业界最流行、最成熟的 4 种具体噪声调度设置方案 (可以直接抄进代码里的那种):
1. Cosine Schedule (余弦调度) —— OpenAI 的经典配方
适用场景 :在像素空间(Pixel-space)直接生成图像,或者做 3D/4D 视觉的基础重建。
为什么好 :最早的线性调度(Linear)在最后几个时间步加噪太猛,导致图像信息瞬间丢失,模型最后全在瞎猜。Cosine 调度让加噪过程变成一条平滑的“S型曲线”,中间慢、两头快,极大地保留了图像的中频细节。
具体设置方案 (公式与参数) :
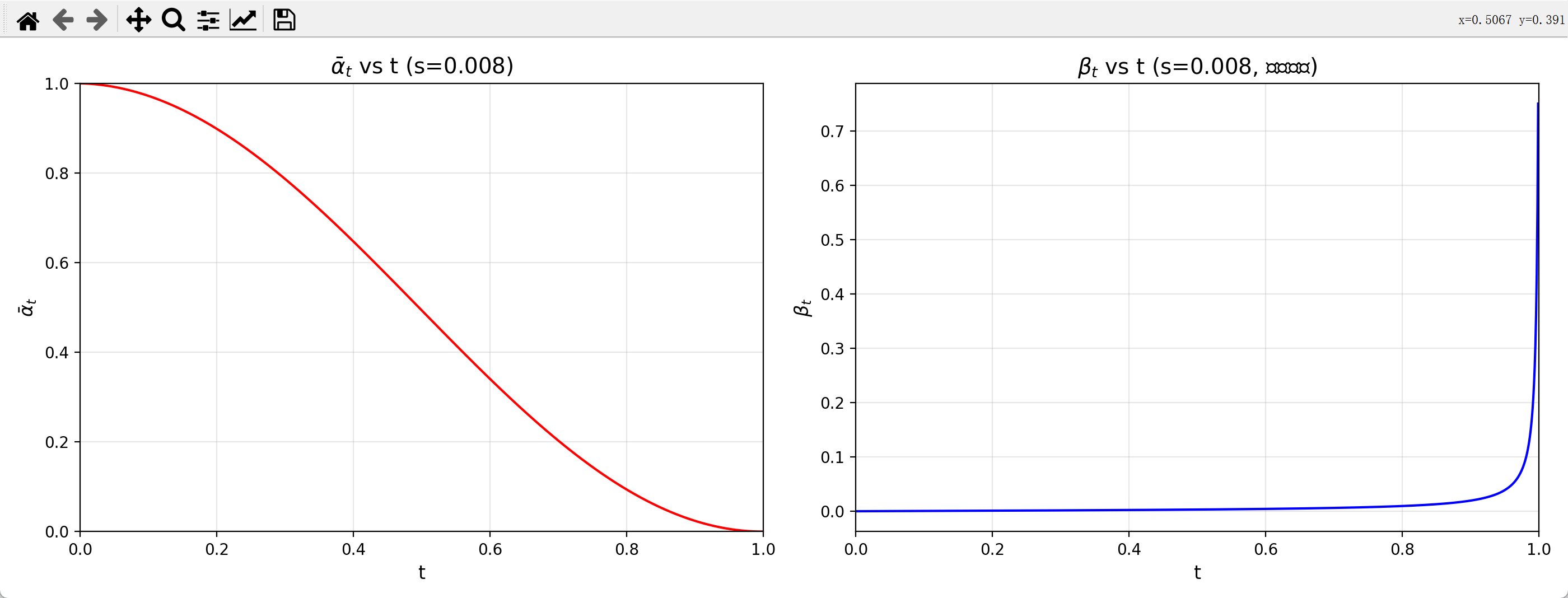
具体函数:α t ˉ = f ( t ) = cos 2 ( t + s 1 + s ⋅ π 2 ) ( t ∈ [ 0 , 1 ] ) \bar{\alpha_t}=f(t) = \cos^2\left( \frac{t + s}{1 + s} \cdot \frac{\pi}{2} \right) (t \in [0,1]) α t ˉ = f ( t ) = cos 2 ( 1 + s t + s ⋅ 2 π ) ( t ∈ [ 0 , 1 ])
定义噪声方差 β t = 1 − α t ˉ α t − 1 ˉ \beta_t =1- \frac{\bar{\alpha_t}}{\bar{\alpha_{t-1}}} β t = 1 − α t − 1 ˉ α t ˉ
核心参数 :偏移量 s = 0.008 s = 0.008 s = 0.008 s s s t = 0 t=0 t = 0
2. Zero-SNR & Enforce Zero (零信噪比调度) —— SD 2.0+ 的补丁
适用场景 :需要生成极暗、极亮图像,或者做高保真图像编辑(Inpainting)。
为什么好 :人们发现标准 VP 调度在最后一步 T T T
具体设置方案 (Lin et al., 2023) :
在代码里强制修改最后一步:原本 α ˉ T \bar{\alpha}_T α ˉ T 10 − 4 10^{-4} 1 0 − 4 强制设置 α ˉ T = 0 \bar{\alpha}_T = 0 α ˉ T = 0 。
同时对前面的时间步进行线性缩放(Rescale),确保曲线平滑。配合 v-prediction 目标函数一起使用,直接解决了图像发灰的问题。
# Convert betas to alphas_bar_sqrt alphas = 1.0 - betas alphas_cumprod = torch . cumprod (alphas, dim = 0 ) alphas_bar_sqrt = alphas_cumprod . sqrt () # Store old values. alphas_bar_sqrt_0 = alphas_bar_sqrt [ 0 ]. clone () alphas_bar_sqrt_T = alphas_bar_sqrt [ - 1 ]. clone () # Shift so the last timestep is zero. alphas_bar_sqrt -= alphas_bar_sqrt_T # Scale so the first timestep is back to the old value. alphas_bar_sqrt *= alphas_bar_sqrt_0 / (alphas_bar_sqrt_0 - alphas_bar_sqrt_T) # Convert alphas_bar_sqrt to betas alphas_bar = alphas_bar_sqrt ** 2 # Revert sqrt alphas = alphas_bar [ 1 :] / alphas_bar [: - 1 ] # Revert cumprod alphas = torch . cat ([alphas_bar[ 0 : 1 ], alphas]) betas = 1 - alphas return betas 3. EDM Schedule (Karras 调度) —— 追求极致质量的工业标准
适用场景 :高分辨率图像生成,当前许多最强二次元模型(如 NovelAI 及其变体)底层的采样策略。
为什么好 :Karras 抛弃了传统的 t t t σ \sigma σ σ \sigma σ
具体设置方案 (来自 EDM 论文的硬核参数) :
训练时采用对数正态分布抽样噪声大小:ln ( σ ) ∼ N ( P m e a n , P s t d 2 ) \ln(\sigma) \sim \mathcal{N}(P_{mean}, P_{std}^2) ln ( σ ) ∼ N ( P m e an , P s t d 2 )
最佳超参数 :P m e a n = − 1.2 P_{mean} = -1.2 P m e an = − 1.2 P s t d = 1.2 P_{std} = 1.2 P s t d = 1.2 采样时(Inference)使用等比数列加上微小的多项式扭曲:
σ i = ( σ m a x 1 ρ + i N − 1 ( σ m i n 1 ρ − σ m a x 1 ρ ) ) ρ \sigma_i = \left( \sigma_{max}^{\frac{1}{\rho}} + \frac{i}{N-1}(\sigma_{min}^{\frac{1}{\rho}} - \sigma_{max}^{\frac{1}{\rho}}) \right)^\rho σ i = ( σ ma x ρ 1 + N − 1 i ( σ min ρ 1 − σ ma x ρ 1 ) ) ρ
最佳超参数 :σ m i n = 0.002 \sigma_{min} = 0.002 σ min = 0.002 σ m a x = 80 \sigma_{max} = 80 σ ma x = 80 ρ = 7 \rho = 7 ρ = 7
4. Rectified Flow / Flow Matching (流匹配) —— 当下最火的绝对主流
适用场景 :Stable Diffusion 3, Flux.1, Sora 以及最新的 3D/视频生成大模型。
为什么好 :不玩 SDE 的弯弯绕绕了,直接用常微分方程 (ODE) 走直线 。从纯噪声到真实图像,两点之间直线最短。这让采样速度发生质变(过去需要 50 步,现在 4-8 步就能出极高质量的图),而且极其容易扩展到高分辨率。
具体设置方案 (Shifted Flow) :
加噪极其简单,就是一个线性组合:x t = t ⋅ noise + ( 1 − t ) ⋅ data x_t = t \cdot \text{noise} + (1 - t) \cdot \text{data} x t = t ⋅ noise + ( 1 − t ) ⋅ data t ∈ [ 0 , 1 ] t \in [0, 1] t ∈ [ 0 , 1 ]
高分辨率的杀手锏 (Time Shifting) :SD3 和 Flux 发现,分辨率越高(比如 1024x1024),图像本身含有的信息量极大,同样的噪声加进去显得“微不足道”。因此他们引入了 Shift 参数 m m m t ′ = m ⋅ t 1 + ( m − 1 ) ⋅ t t' = \frac{m \cdot t}{1 + (m - 1) \cdot t} t ′ = 1 + ( m − 1 ) ⋅ t m ⋅ t 具体参数 :对于 256x256 图像 m ≈ 1 m \approx 1 m ≈ 1 m m m 3.0 3.0 3.0 


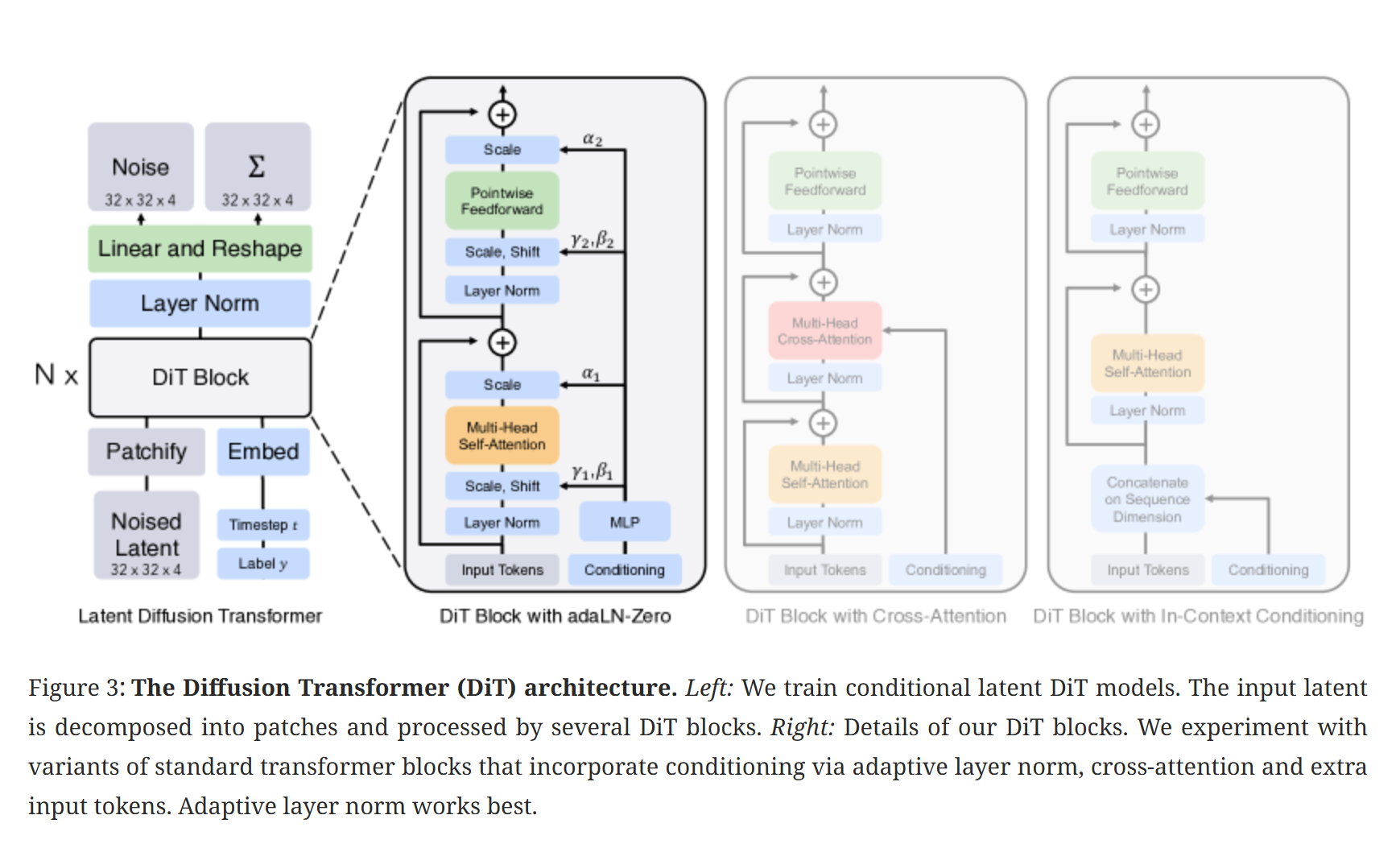 这张图已然说明一切.
这张图已然说明一切.